语音识别(ASR)论文优选:关注语音识别系统Fairness问题Towards Measuring Fairness in Speech Recognition
对于ASR模型的偏差研究,因此本文提供了带诸多metadata属性的闲聊Casual Conversations语音测试集,并进行ASR偏差实验和影响因素的探索,为探索更加鲁棒的识别系统做贡献。
声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。语音合成领域论文列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。如何查找语音资料请参考文章https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg)。如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
Towards Measuring Fairness in Speech Recognition: Casual Conversations Dataset Transcriptions
本文为facebook在2021.11.18更新的文章,主要开源一个带诸多metadata属性(性别,年龄,肤色等等)的闲聊Casual Conversations语音测试集,并使用该测试集对ASR系统进行fairness评估,发掘更多影响ASR效果的诸多因素,为开发更加鲁棒的ASR系统做贡献,具体的文章链接
https://arxiv.org/pdf/2111.09983.pdf
1 研究背景
机器学习系统中的算法偏差问题广为人知并得到充分研究,诸如面部视觉系统受到肤色、年龄等等因素的影响,但对于ASR模型的偏差研究的关注度非常低,因此本文提供了带诸多metadata属性(性别,年龄,肤色等等)的闲聊Casual Conversations语音测试集,并进行ASR偏差实验和影响因素的探索,为探索更加鲁棒的识别系统做贡献,省却搜集大量的特定目标人的训练语料。
2 详细实验
数据从846小时数据整理和标注572小时,数据包括音频、对应的标注文本、说话人的性别、年龄、肤色等信息。
对比的四个系统RNN-T
1)LibriSpeech Model:使用LibriSpeech训练的模型
2)video model, supervised: 使用带标注的14k小时的数据训练新型模型
3)video model, semi-supervised: 使用带标注的14k小时的数据和2百万无标签的数据训练新型模型
4)video model, semi-supervised teacher: 使用10亿参数的teacher模型
对比影响因素:性别,年龄,肤色。其中肤色看起来不会直接影响ASR,但它代表隐含因素对系统影响。
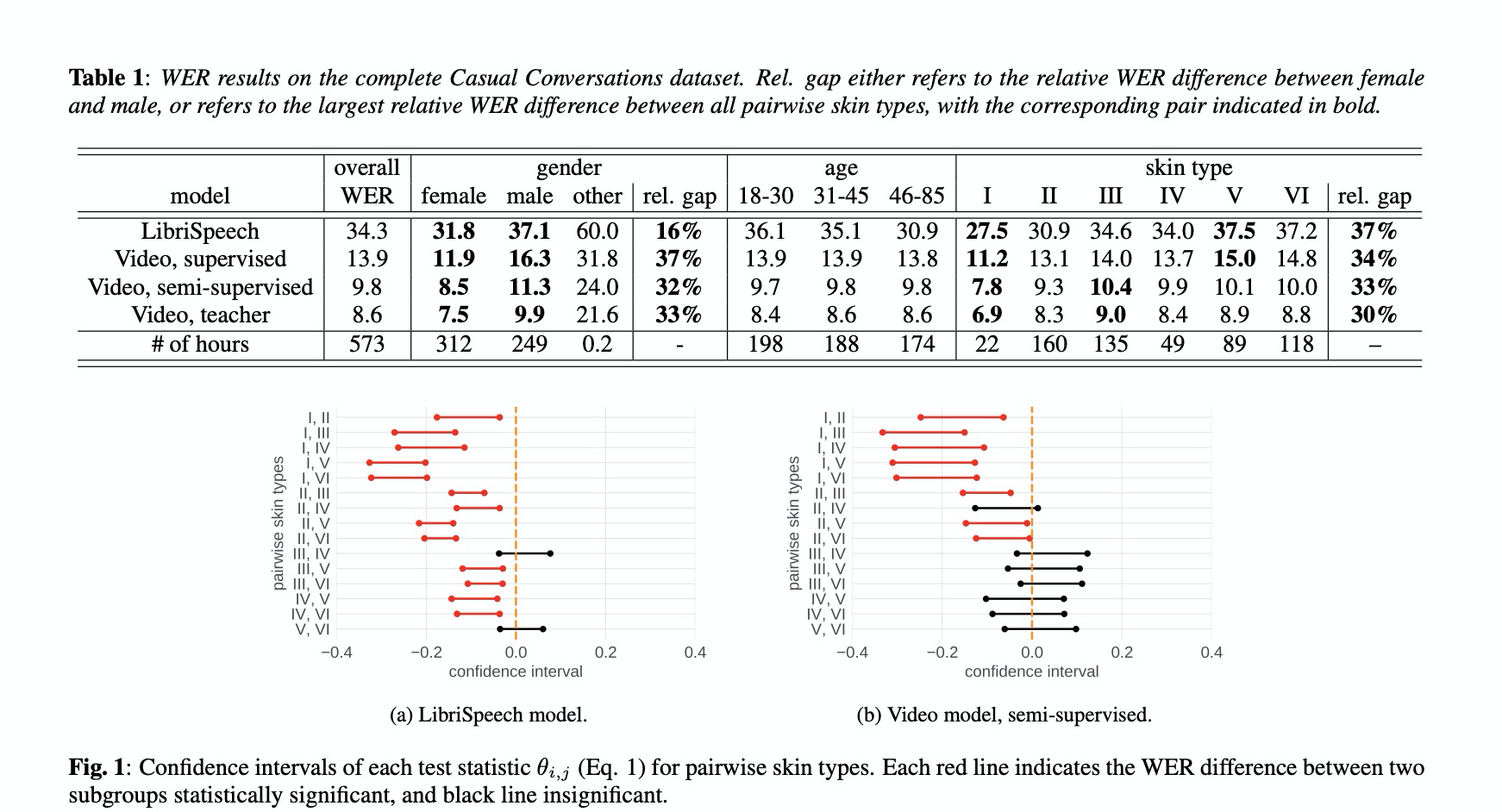
实验结果:
先看table1的结果,每种系统的WER不一样,这个不在本文的探索之内。可以观测到性别和肤色影响因素对系统的影响很大,整体偏向女性效果较好。另外,年龄之间影响差别较小。Fig.1展示了各种肤色的测CI,如果包括零则差别不大,如黑色线。红色线代表差别大。LibriSpeech的肤色影响较重,Video semi-supervised稍微好一些,可能跟2百万的数据覆盖更多属性有关。Table2是使用本文闲聊数据划分部分数据进行微调,即使wer整体下降,但不能降低各因素之间的偏差,需要研究更深层次的影响因素。

3 总结
对于ASR模型的偏差研究,因此本文提供了带诸多metadata属性的闲聊Casual Conversations语音测试集,并进行ASR偏差实验和影响因素的探索,为探索更加鲁棒的识别系统做贡献。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)