facebook开源新的语音识别框架wav2letter++
Open sourcing wav2letter++, the fastest state-of-the-art speech system, and flashlight, an ML library going native原文介绍:https://code.fb.com/ai-research/wav2letter/主要介绍了使用CNN来实现语音识别的方法WHAT T...
Open sourcing wav2letter++, the fastest state-of-the-art speech system, and flashlight, an ML library going native
原文介绍:https://code.fb.com/ai-research/wav2letter/
主要介绍了使用CNN来实现语音识别的方法
WHAT THE RESEARCH IS:
A new fully convolutional approach to automatic speech recognition and wav2letter++, the fastest state-of-the-art end-to-end speech recognition system available. The approach leverages convolutional neural networks (CNNs) for acoustic modeling and language modeling, and is reproducible, thanks to the toolkits we are releasing jointly.
HOW IT WORKS:
CNN architectures are competitive with recurrent architectures for tasks in which modeling long-range dependencies is important, such as language modeling, machine translation, and speech synthesis. In end-to-end speech recognition, however, recurrent architectures are still more prevalent for both acoustic and language modeling.
The Facebook AI Research (FAIR) Speech team is sharing the first fully convolutional speech recognition system. From the waveform to the final word transcription, the learnable parts of the system are composed only of convolutional layers. This yields performance that’s competitive with that of recurrent architectures.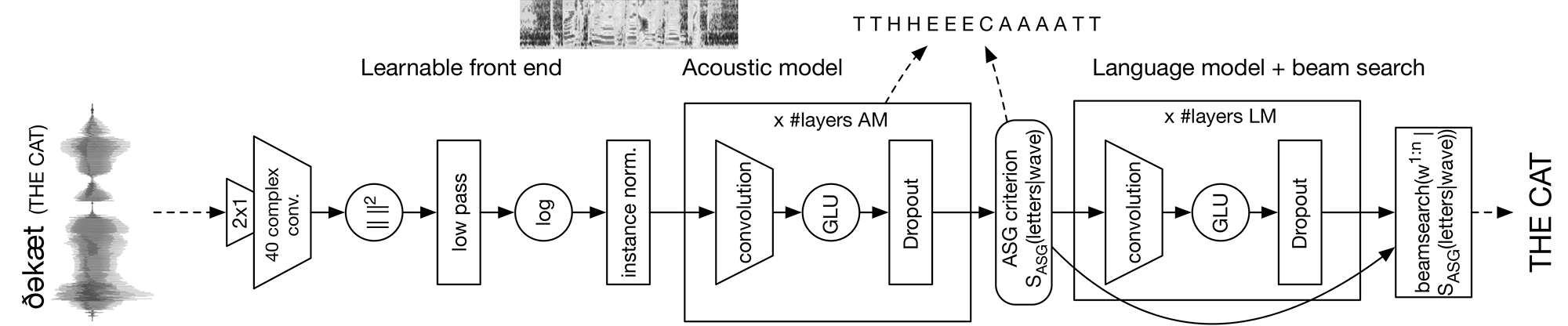
We are also releasing flashlight, a fast, flexible standalone machine learning library designed by the FAIR Speech team and the creators of Torch and DeepSpeech. It features just-in-time compilation with modern C++, targeting both CPU and GPU backends for maximum efficiency and scale. The wav2letter++ toolkit is built on top of flashlight. We are releasing both frameworks jointly with this research to enable reproducibility.
WHY IT MATTERS:
End-to-end speech recognition makes it easy to scale to multiple languages. Also, learning directly from raw speech is a promising avenue in settings where audio quality is highly variable. High-performance frameworks such as wav2letter++ enable fast iteration, which is often an important factor in successful research and model tuning on new data sets and tasks.
READ THE FULL PAPERS:
Wav2letter++: The fastest open source speech recognition system and Fully Convolutional Speech Recognition
知乎: https://zhuanlan.zhihu.com/albertwang
微信公众号:AI-Research-Studio

下面是赞赏码



CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)