Kaldi中DNN的实现
在 kaldi 训练过程中,DNN 的训练是主要是依赖于 GMM-HMM 模型的,通过 GMM-HMM 模型得到 DNN 声学模型的输出结果(在 get_egs.sh 脚本中可以看到这一过程)。因此训练一个好的 GMM-HMM 模型是 kaldi 语音识别的关键。所以在run.sh中可以看到,GMM-HMM 训练了 5 次,得到一个相对比较不错的模型,然后训练 nnet3 模型以及 chain 模
·
本文主要讲解kaldi中run.sh和run_tdnn.sh的代码,从中了解Kaldi的DNN的实现。
在 kaldi 训练过程中,DNN 的训练是主要是依赖于 GMM-HMM 模型的,通过 GMM-HMM 模型得到 DNN 声学模型的输出结果(在 get_egs.sh 脚本中可以看到这一过程)。因此训练一个好的 GMM-HMM 模型是 kaldi 语音识别的关键。
所以在run.sh中可以看到,GMM-HMM 训练了 5 次,得到一个相对比较不错的模型,然后训练 nnet3 模型以及 chain 模型,最后测试精度。
整体过程如图:
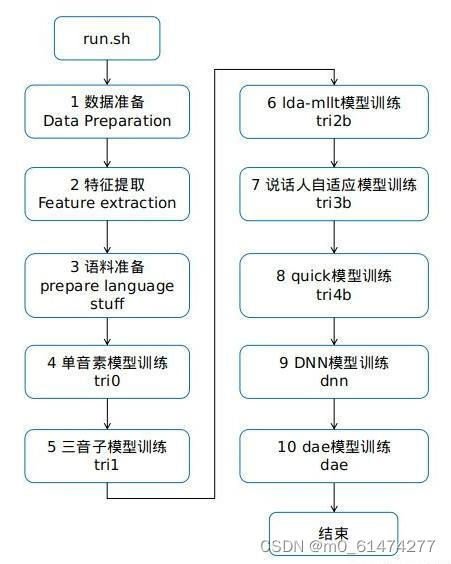
# Train a monophone model on delta features.训练单音素HMM模型,每两次迭代进行一次对齐操作
#主要是对齐音素和每一帧音频
steps/train_mono.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/mono || exit 1;
# Decode with the monophone model.单音素解码,生成了用于解码的HCLG.fst
utils/mkgraph.sh data/lang_test exp/mono exp/mono/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/mono/graph data/dev exp/mono/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/mono/graph data/test exp/mono/decode_test
# Get alignments from monophone system. 从单音素系统中获取对齐方式
steps/align_si.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/mono exp/mono_ali || exit 1;
# Train the first triphone pass model tri1 on delta + delta-delta features. 训练与上下文相关的三音子模型
steps/train_deltas.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/mono_ali exp/tri1 || exit 1;
# decode tri1 #三音素解码
utils/mkgraph.sh data/lang_test exp/tri1 exp/tri1/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri1/graph data/dev exp/tri1/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri1/graph data/test exp/tri1/decode_test
# align tri1 校准
steps/align_si.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri1 exp/tri1_ali || exit 1;
# train tri2 [delta+delta-deltas] 同上
steps/train_deltas.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/tri1_ali exp/tri2 || exit 1;
# decode tri2
utils/mkgraph.sh data/lang_test exp/tri2 exp/tri2/graph
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri2/graph data/dev exp/tri2/decode_dev
steps/decode.sh --cmd "$decode_cmd" --config conf/decode.config --nj 10 \
exp/tri2/graph data/test exp/tri2/decode_test
# Align training data with the tri2 model.
steps/align_si.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri2 exp/tri2_ali || exit 1;
# Train the second triphone pass model tri3a on LDA+MLLT features. tri3a上加上lda + mllt。用来进行线性判别分析和最大似然线性转换
steps/train_lda_mllt.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/tri2_ali exp/tri3a || exit 1;
# Run a test decode with the tri3a model.
utils/mkgraph.sh data/lang_test exp/tri3a exp/tri3a/graph || exit 1;
steps/decode.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri3a/graph data/dev exp/tri3a/decode_dev
steps/decode.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri3a/graph data/test exp/tri3a/decode_test
# align tri3a with fMLLR
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri3a exp/tri3a_ali || exit 1;
# Train the third triphone pass model tri4a on LDA+MLLT+SAT features.
# From now on, we start building a more serious system with Speaker
# Adaptive Training (SAT). 加上说话人SAT进行自然语言训练,训练发音人自适应
steps/train_sat.sh --cmd "$train_cmd" \
2500 20000 data/train data/lang exp/tri3a_ali exp/tri4a || exit 1;
# decode tri4a
utils/mkgraph.sh data/lang_test exp/tri4a exp/tri4a/graph
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri4a/graph data/dev exp/tri4a/decode_dev
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri4a/graph data/test exp/tri4a/decode_test
# align tri4a with fMLLR
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri4a exp/tri4a_ali
# Train tri5a, which is LDA+MLLT+SAT
# Building a larger SAT system. You can see the num-leaves is 3500 and tot-gauss is 100000
steps/train_sat.sh --cmd "$train_cmd" \
3500 100000 data/train data/lang exp/tri4a_ali exp/tri5a || exit 1;
# decode tri5a
utils/mkgraph.sh data/lang_test exp/tri5a exp/tri5a/graph || exit 1;
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri5a/graph data/dev exp/tri5a/decode_dev || exit 1;
steps/decode_fmllr.sh --cmd "$decode_cmd" --nj 10 --config conf/decode.config \
exp/tri5a/graph data/test exp/tri5a/decode_test || exit 1;
# align tri5a with fMLLR
steps/align_fmllr.sh --cmd "$train_cmd" --nj 10 \
data/train data/lang exp/tri5a exp/tri5a_ali || exit 1;
# nnet3
local/nnet3/run_tdnn.sh
# chain
local/chain/run_tdnn.sh
# getting results (see RESULTS file)
for x in exp/*/decode_test; do [ -d $x ] && grep WER $x/cer_* | utils/best_wer.sh; done 2>/dev/null
for x in exp/*/*/decode_test; do [ -d $x ] && grep WER $x/cer_* | utils/best_wer.sh; done 2>/dev/null
exit 0;
以下是run_tdnn.sh的代码
#!/usr/bin/env bash
# This script is based on swbd/s5c/local/nnet3/run_tdnn.sh
# this is the standard "tdnn" system, built in nnet3; it's what we use to
# call multi-splice.
# At this script level we don't support not running on GPU, as it would be painfully slow.
# If you want to run without GPU you'd have to call train_tdnn.sh with --gpu false,
# --num-threads 16 and --minibatch-size 128.
set -e
stage=0
train_stage=-10
affix=
common_egs_dir=
# training options
initial_effective_lrate=0.0015
final_effective_lrate=0.00015
num_epochs=4
num_jobs_initial=2
num_jobs_final=12
remove_egs=true
# feature options
use_ivectors=true
# End configuration section.
. ./cmd.sh
. ./path.sh
. ./utils/parse_options.sh
if ! cuda-compiled; then
cat <<EOF && exit 1
This script is intended to be used with GPUs but you have not compiled Kaldi with CUDA
If you want to use GPUs (and have them), go to src/, and configure and make on a machine
where "nvcc" is installed.
EOF
fi
dir=exp/nnet3/tdnn_sp${affix:+_$affix}
#此处是设置了GMM输入的参数目录
gmm_dir=exp/tri5a
train_set=train_sp
#对齐后的特征集合目录
ali_dir=${gmm_dir}_sp_ali
graph_dir=$gmm_dir/graph
local/nnet3/run_ivector_common.sh --stage $stage || exit 1;
if [ $stage -le 7 ]; then
echo "$0: creating neural net configs";
num_targets=$(tree-info $ali_dir/tree |grep num-pdfs|awk '{print $2}')
#进行kaldi的DNN网络配置
mkdir -p $dir/configs
cat <<EOF > $dir/configs/network.xconfig
input dim=100 name=ivector
input dim=43 name=input
# please note that it is important to have input layer with the name=input
# as the layer immediately preceding the fixed-affine-layer to enable
# the use of short notation for the descriptor
fixed-affine-layer name=lda input=Append(-2,-1,0,1,2,ReplaceIndex(ivector, t, 0)) affine-transform-file=$dir/configs/lda.mat
# the first splicing is moved before the lda layer, so no splicing here
relu-batchnorm-layer name=tdnn1 dim=850
relu-batchnorm-layer name=tdnn2 dim=850 input=Append(-1,0,2)
relu-batchnorm-layer name=tdnn3 dim=850 input=Append(-3,0,3)
relu-batchnorm-layer name=tdnn4 dim=850 input=Append(-7,0,2)
relu-batchnorm-layer name=tdnn5 dim=850 input=Append(-3,0,3)
relu-batchnorm-layer name=tdnn6 dim=850
output-layer name=output input=tdnn6 dim=$num_targets max-change=1.5
EOF
#将网络配置转换为nnet3的网络配置文件
steps/nnet3/xconfig_to_configs.py --xconfig-file $dir/configs/network.xconfig --config-dir $dir/configs/
fi
if [ $stage -le 8 ]; then
if [[ $(hostname -f) == *.clsp.jhu.edu ]] && [ ! -d $dir/egs/storage ]; then
utils/create_split_dir.pl \
/export/b0{5,6,7,8}/$USER/kaldi-data/egs/aishell-$(date +'%m_%d_%H_%M')/s5/$dir/egs/storage $dir/egs/storage
fi
#执行 train_dnn.py来对feats内容进行训练
steps/nnet3/train_dnn.py --stage=$train_stage \
--cmd="$decode_cmd" \
--feat.online-ivector-dir exp/nnet3/ivectors_${train_set} \
--feat.cmvn-opts="--norm-means=false --norm-vars=false" \
--trainer.num-epochs $num_epochs \
--trainer.optimization.num-jobs-initial $num_jobs_initial \
--trainer.optimization.num-jobs-final $num_jobs_final \
--trainer.optimization.initial-effective-lrate $initial_effective_lrate \
--trainer.optimization.final-effective-lrate $final_effective_lrate \
--egs.dir "$common_egs_dir" \
--cleanup.remove-egs $remove_egs \
--cleanup.preserve-model-interval 500 \
--use-gpu true \
--feat-dir=data/${train_set}_hires \
--ali-dir $ali_dir \
--lang data/lang \
--reporting.email="$reporting_email" \
--dir=$dir || exit 1;
fi
if [ $stage -le 9 ]; then
# this version of the decoding treats each utterance separately
# without carrying forward speaker information.
for decode_set in dev test; do
num_jobs=`cat data/${decode_set}_hires/utt2spk|cut -d' ' -f2|sort -u|wc -l`
decode_dir=${dir}/decode_$decode_set
steps/nnet3/decode.sh --nj $num_jobs --cmd "$decode_cmd" \
--online-ivector-dir exp/nnet3/ivectors_${decode_set} \
$graph_dir data/${decode_set}_hires $decode_dir || exit 1;
done
fi
wait;
exit 0;
CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)