【论文笔记】Applying Differential Privacy Mechanism in Artificial Intelligence
【论文笔记】Applying Differential Privacy Mechanism in Artificial Intelligence论文摘要:近年来,人工智能(AI)吸引了大量关注。但是,出现了一些新问题,例如侵犯隐私,安全问题或有效性。差异隐私具有几个吸引人的属性,这些属性使其对AI相当有价值,例如隐私保护,安全性,随机性,组成和稳定性。因此,本文基于这些特性提出了用于多主体系统,强
【论文笔记】Applying Differential Privacy Mechanism in Artificial Intelligence
论文摘要:
近年来,人工智能(AI)吸引了大量关注。但是,出现了一些新问题,例如侵犯隐私,安全问题或有效性。差异隐私具有几个吸引人的属性,这些属性使其对AI相当有价值,例如隐私保护,安全性,随机性,组成和稳定性。因此,本文基于这些特性提出了用于多主体系统,强化学习和知识转移的差异隐私机制,证明了当前的AI可以从差异隐私机制中受益。此外,还讨论了差异隐私机制在私有机器学习,分布式机器学习和模型公平性中的先前用法,从而为在AI中使用差异隐私机制提供了几种可能的途径。本文的目的是提供有关如何将AI与不同的隐私机制集成的初步想法,并探索提高AI性能的更多可能性。
论文内容整理
1、Introduction中提到的可以差分隐私和AI相性相符的几个点:
- 保护隐私
- 稳定性:保证了模型的输出不受单条记录的影响,算法的泛化能力加强
- 安全性:减少恶意攻击者对于AI任务的影响
- 随机性:差分隐私的随机性使得某些算法可以因此受益
- 组合性
2、DP 和 Multi-agent system 的结合
在多代理系统中,单个agent的决策依赖于多个邻居agent和本身的信息,因此存在恶意agent进行攻击的可能。因此,可以考虑将差分隐私机制应用到其中。
采用指数机制来决定使用哪个agent的信息,并且设立赏罚向量。(问题:一般来说,多个agent都被使用到才合理,不应该只使用某个agent)
然后进一步引出强化学习和迁移学习。因为赏罚向量是强化学习的内容,而agent之间的信息交流,使用知识迁移则可以归入迁移学习范畴。
而在知识迁移过程中所需要考虑到的问题有:
- 是否需要请求知识
- 要从何者处请求
- 是否提供知识
- 如何传递知识
不同隐私的随机化性质可以用于强化学习,以保证体现在一个观察中的知识可以在不同的观察下转移。在“如何传递知识”中可以采用不同的隐私机制,让玩家分享不同的知识。
一个知识迁移的图例:
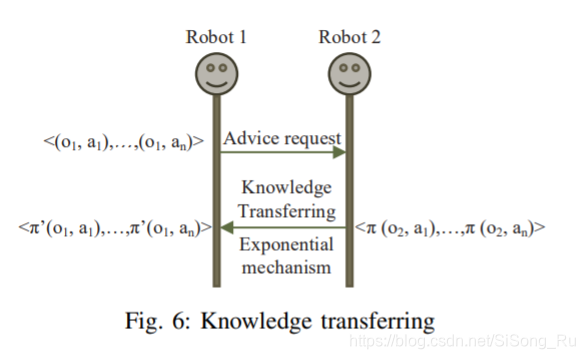
此处使用到差分隐私的知识迁移算法如下:
利用指数机制,调整原有的概率分布,使得其符合差分隐私性质,既能保护隐私,又能防止恶意攻击。

3、差分隐私和稳定的机器学习算法
个稳定的学习算法是指当训练数据稍微修改时,预测不会发生太大的变化。Bousquet等[3]证明了该学习算法的稳定性与泛化误差界有关。结果表明,高稳定性算法会更少的过拟合。
差分隐私的定义可以自然地与学习稳定性的要求联系起来,学习稳定性保证了通过修改任何单个记录观察分析结果的概率本质上是不变的。Dwork等[9]、[10]已经证明,差分隐私机制可用于开发具有可证明边界的自适应数据分析算法,用于过拟合。某些稳定概念对于推广是必要和充分的。
在数据分析过程中加入随机性来减少过拟合的想法已经被广泛接受。MacCoun等人[22]支持盲数据分析:在决定报告哪些结果时,分析师与数据集进行交互,该数据集已经通过向观察数据添加噪声、删除一些数据点或切换数据标签而变得模糊。未损坏的原始数据集仅用于计算最终报告的值。不同的隐私机制可以遵循上述规则,显著改善过拟合约束
4、差分隐私和公平性模型
近年来,人们越来越关注机器学习算法中可能存在的不公平,比如种族歧视[21]。“公平”通常来自于训练数据的偏差:经过训练,根据历史数据做出决策的系统会自然地继承过去的偏差。在最近的研究中提出了两种公平定义:一种是群体公平,即受保护群体中接受积极分类的成员比例与整个群体中的比例相同;以及个人公平。
一些工作旨在通过一种公平性调节器调整标准学习方法,或通过重新标记训练数据[21]来实现公平性。差异隐私机制试图通过定义从个体到中间表示[11]的概率映射来实现群体和个体的公平性。
在公平性模型中,相似度的度量、组成等都是有待解决的问题。除此之外,公平模型中的差异隐私也集中在分类问题上。
还有一些研究是关于在线学习、土匪学习和强化学习的公平性的。如何利用不同的隐私机制来造福那些网上设置的公平需要进一步的研究

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)