【反爬虫】Scrapy设置随机请求头
随机User-Agent的构建在这里给大家推荐一个包含全球所有的user-agent的网站:网站地址效果图如下:这里我随机选了几个关于谷歌和火狐浏览器中的UA,然后再scrapy框架中的middlewares.py中新增加一个类,在里面构建了一个user-agent的列表,效果如下:```pythonclass UserAgentDownloadMiddleware(object...
随机User-Agent的构建
在这里给大家推荐一个包含全球所有的user-agent的网站:
网站地址
效果图如下:

这里我随机选了几个关于谷歌和火狐浏览器中的UA,然后再scrapy框架中的middlewares.py中新增加一个类
,在里面构建了一个user-agent的列表,效果如下:
```python
class UserAgentDownloadMiddleware(object):
UA = [
{"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"},
{"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"},
{"user-agent": "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/44.0.2403.155 Safari/537.36"},
{"user-agent": "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.3) Gecko/20100409 Firefox/3.6.3 CometBird/3.6.3"},
{"user-agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.0.5) Gecko/2009011615 Firefox/3.0.5 CometBird/3.0.5"}
]
然后再类中重新定义process_request(self, request, spider 函数,用来随机选择UA中的user-agent
首先导入random模块
user_agent = random.choice(self.UA)["user-agent"]
request.headers["user-agent"] = user_agent
所以完整的middleware中的设置就完成了,随后在settings中开启这个类
DOWNLOADER_MIDDLEWARES = {
'useragnet_demo.middlewares.UserAgentDownloadMiddleware': 543,
}
设置完成之后打开spiders目录下的项目文件,这里我使用的是请求头测试链接
来测试我的user-agent,首先在parse方法中利用json模块将response.text内容转换成字典,然后取出其中的“user-agent”
然后将它打印出来,为了能够看到更好的效果,所以这里就使用生成器将开始的url地址进行请求,因为scarpy框架有url去重功能,为了多次请求同一个url,所以将里面的dont_filter设为True, 代码如下:
# -*- coding: utf-8 -*-
import scrapy
import json
class UaSpider(scrapy.Spider):
name = 'UA'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/user-agent']
def parse(self, response):
user_agent = json.loads(response.text)["user-agent"]
print("*" * 30)
print(user_agent)
print("*" * 30)
yield scrapy.Request(self.start_urls[0], dont_filter=True)
然后就可以运行程序了,运行之后的结果如下:
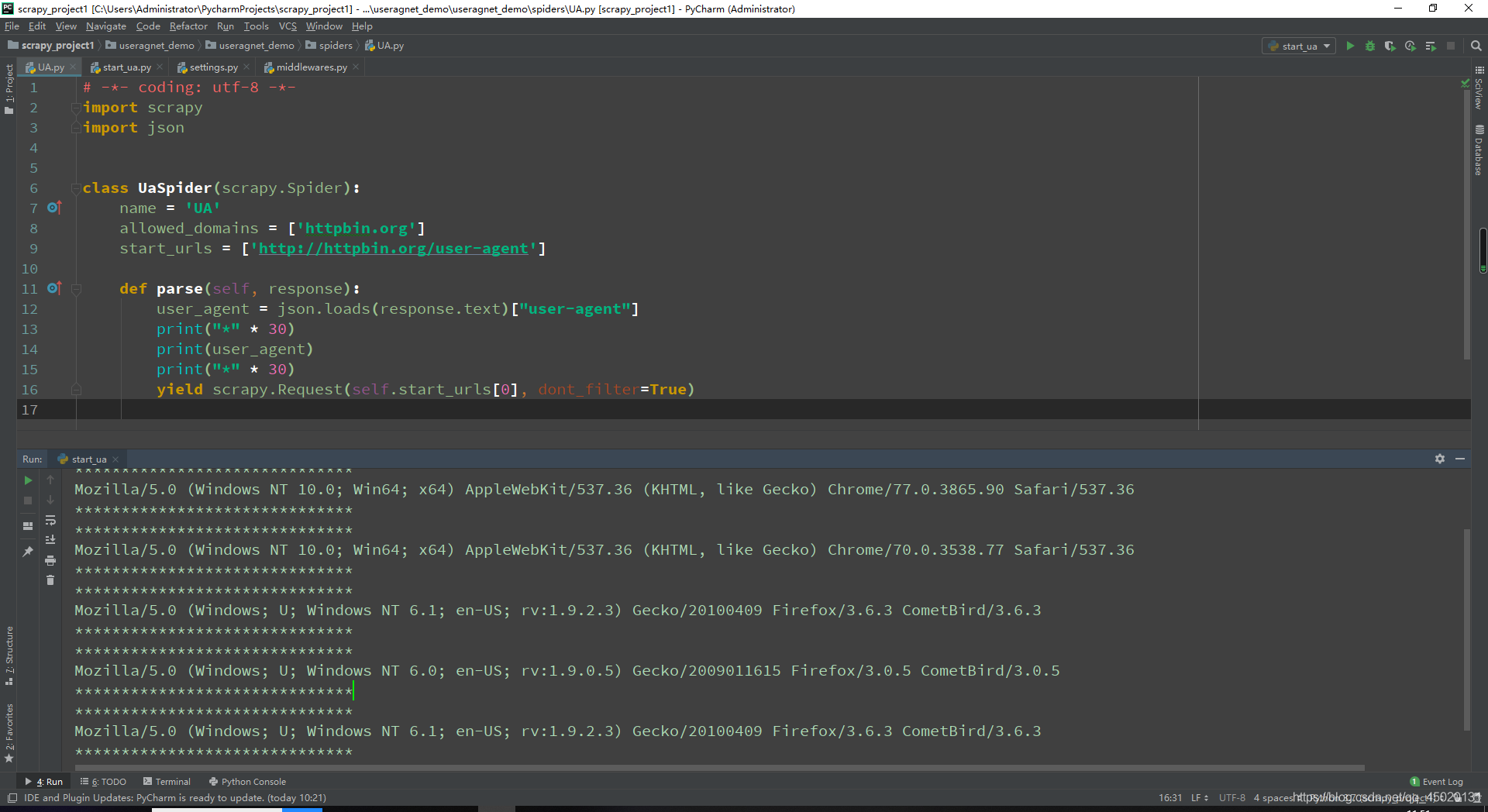
可以看到,随机的user-agent就完成啦.

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)