plt绘制平滑曲线_一点点数据分析|利用鸢尾花数据集绘制P-R曲线图
#文章首发于公众号“如风起”。原文链接:一点点数据分析|利用鸢尾花数据集绘制P-R曲线图mp.weixin.qq.comPython版本:Python 3.8.0 操作平台:jupyter notebook使用的库:matplotlib、numpy、sklearn实现目标:利用鸢尾花数据集绘制P-R曲线图鸢尾花数据集(Iris data set)作为一个经典的数据集,在统计学习、模式识别、机器

#文章首发于公众号“如风起”。
原文链接:
一点点数据分析|利用鸢尾花数据集绘制P-R曲线图mp.weixin.qq.com
Python版本:Python 3.8.0
操作平台:jupyter notebook
使用的库:matplotlib、numpy、sklearn
实现目标:利用鸢尾花数据集绘制P-R曲线图
鸢尾花数据集(Iris data set)作为一个经典的数据集,在统计学习、模式识别、机器学习等领域里被广泛使用。
维基百科里面对鸢尾花数据集是这样介绍的:
安德森鸢尾花卉数据集(Anderson's Iris data set),也称鸢尾花卉数据集(Iris flower data set)或费雪鸢尾花卉数据集(Fisher's Iris data set),是一类多重变量分析的数据集。它最初是埃德加·安德森从加拿大加斯帕半岛上的鸢尾属花朵中提取的形态学变异数据,后由罗纳德·费雪作为判别分析的一个例子,运用到统计学中。
其数据集包含了150个样本,都属于鸢尾属下的三个亚属,分别是山鸢尾、变色鸢尾和维吉尼亚鸢尾。四个特征被用作样本的定量分析,它们分别是花萼和花瓣的长度和宽度。基于这四个特征的集合,费雪发展了一个线性判别分析以确定其属种。
基于鸢尾花数据集的不同软件的各类数据分析也是非常的多。这里整理复现中国大学MOOC(慕课)上哈尔滨工业大学刘远超老师的《深度学习基础》中的利用鸢尾花数据集绘制P-R曲线的Python程序。
首先,我们导入本次代码所需要的Python的模块。
import matplotlib.pyplot as plt
import numpy as np
from sklearn import svm, datasets
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
#from sklearn.cross_validation import train_test_split #适用于anaconda 3.6及以前版本
from sklearn.model_selection import train_test_split #适用于anaconda 3.7及以后版本- 第一行是导入matplotlib中的pyplot模块,用于绘制图像;
- 第二行是导入numpy包,用于处理矩阵运算;
- 第三行是导入sklearn中的svm(支持向量机)模块以及datasets(数据集)模块;
- 第四行是导入precision_recall_curve(精确率、召回率评价曲线)模块;
- 第五行是导入average_precision_score(平均精确率分数,等于P-R曲线下的面积)模块;
- 第六行是导入label_binarize(标签二值化处理)模块;
- 第七行是导入OneVsRestClassifier(一对其余)模块,每次将其中一个类作为正类,其余类作为负类;
- 第八、第九行是导入train_test_split(训练集、测试集的拆分模块),第八行的代码适用于anaconda 3.6及以前版本,第九行的代码适用于anaconda 3.7及之后的版本。
其中,第六、第七行模块的作用是:因为鸢尾花分类问题是多类别的分类问题(三类),所以我们需要先将鸢尾花进行二值化处理,即将鸢尾花的三个类转化为001、010、100的格式,之后我们需要通过OneVsRestClassifier将其转换为两类的分类问题进行处理。
接下来,我们导入并查看鸢尾花数据集,这里我们直接使用datasets加载数据集。
iris = datasets.load_iris()
iris

type(iris)
可以看到,iris是一个Bunch类。
Bunch和字典结构类似,也是由键值对组成,和字典区别:其键值可以被实例对象当作属性使用。
- Bunch的属性有:
- data:数据数组。
- target:文件分类。如鸢尾花三类的,与filenames一一对应为0、1、2。
- target_names:标签名。可以自定义,默认为文件夹名。
- DESCR:数据描述。
- filenames:文件名。
数据集加载完成之后,我们定义鸢尾花数据集中的数据特征和标签。定义X为鸢尾花数据集输入样本特征矩阵,y为鸢尾花数据集输出类别标签矩阵。
X = iris.data
y = iris.target
print(X.shape,y.shape)
因为鸢尾花数据集中鸢尾花有四个特征,所以X的维度是150x4,y的维度是150x1。
然后,我们利用label_binarize将鸢尾花的类别进行二值化处理,即将鸢尾花的三个类转化为001、010、100的格式。
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]下一步,我们对X增加800维噪声特征,来增加分离难度。
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]其中,np.random.RandomState()是一个伪随机数生成器。
伪随机数是用确定性的算法计算出来的来自[0,1]均匀分布的随机数序列。并不真正的随机,但具有类似于随机数的统计特征,如均匀性、独立性等。
通过np.c_[ ]在原始X矩阵的基础上增加800维噪声特征。
紧接着,我们对X和y进行训练集和测试集的拆分,设置拆分比例为0.5。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5, random_state=random_state)然后,我们调用OneVsRestClassifier模块将分类问题转换为两类的分类问题从而构建一个新的分类器。基本的分类器仍使用SVM。
classifier = OneVsRestClassifier(svm.SVC(kernel='linear', probability=True, random_state=random_state))紧接着,我们将训练集输入分类器中进行拟合训练,训练完成之后,我们将测试集中的样本特征输入进去,从而得到测试集中每个样本的预测分数y_score。
y_score = classifier.fit(X_train, y_train).decision_function(X_test)最后一部分,我们计算每一个类别的精确率和召回率,并绘制鸢尾花数据集的P-R曲线图。
首先,定义三个字典precision、recall、average_precision。
precision = dict()
recall = dict()
average_precision = dict()然后,我们计算每一个类的精确率和召回率以及平均精确率分数。
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(y_test[:, i], y_score[:, i])
average_precision[i] = average_precision_score(y_test[:, i], y_score[:, i])其中,下划线"_"是返回的阈值。作为一个名称:此时"_"作为临时性的名称使用,表示分配了一个特定的名称,但是并不会在后面再次用到该名称。
之后,我们计算微平均值。
precision["micro"], recall["micro"], _ = precision_recall_curve(y_test.ravel(), y_score.ravel())
average_precision["micro"] = average_precision_score(y_test, y_score, average="micro")其中,ravel()函数可以将多维数组降为一维。
最后,我们绘制鸢尾花数据集绘制P-R曲线。
# Plot Precision-Recall curve for each class
plt.style.use('seaborn') #选择'seaborn'画布分格,使绘图美观一点
plt.clf()#clf 函数用于清除当前图像窗口
plt.plot(recall["micro"], precision["micro"],
label='micro-average Precision-recall curve (area = {0:0.2f})'.format(average_precision["micro"]))
for i in range(n_classes):
plt.plot(recall[i], precision[i],
label='Precision-recall curve of class {0} (area = {1:0.2f})'.format(i, average_precision[i]))
#xlim、ylim:分别设置X、Y轴的显示范围。
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
#设置横纵坐标标题
plt.xlabel('Recall', fontsize=16)
plt.ylabel('Precision',fontsize=16)
#设置P-R图的标题
plt.title('Extension of Precision-Recall curve to multi-class',fontsize=16)
plt.legend(loc="lower right")#legend 是用于设置图例的函数
plt.show()最终,我们得到鸢尾花数据集的P-R曲线如下图所示。
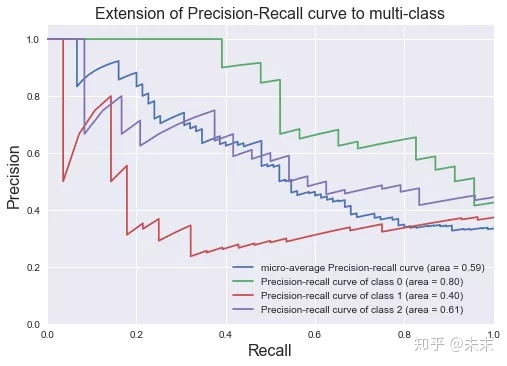
其中,不同颜色的线代表着不同类别鸢尾花的P-R曲线,蓝色的线则表示其余三条线的平均值。
参考资料
[1]刘远超.深度学习基础[EB/OL].(2020-05-7)[2020-7-7]. https://www. icourse163.org/learn/HI T-1206320802?tid=1450221457#/learn/content?type=detail&id=1214431005&cid=1218104374&replay=true
附录:
完整的绘图代码
#导入所需要的模块
import matplotlib.pyplot as plt
import numpy as np
from sklearn import svm, datasets
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
#from sklearn.cross_validation import train_test_split #适用于anaconda 3.6及以前版本
from sklearn.model_selection import train_test_split #适用于anaconda 3.7及以后版本
#导入鸢尾花数据集
iris = datasets.load_iris()
iris
type(iris)
#定义鸢尾花数据集中的数据特征和标签
X = iris.data
y = iris.target
print(X.shape,y.shape)
#将鸢尾花的类别进行二值化处理
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
#对X增加800维噪声特征
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
#对X和y进行训练集和测试集的拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5, random_state=random_state)
#构建分类器,训练模型
classifier = OneVsRestClassifier(svm.SVC(kernel='linear', probability=True, random_state=random_state))
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
#计算每一个类别的精确率和召回率,并绘制鸢尾花数据集的P-R曲线图
precision = dict()
recall = dict()
average_precision = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(y_test[:, i], y_score[:, i])
average_precision[i] = average_precision_score(y_test[:, i], y_score[:, i])
precision["micro"], recall["micro"], _ = precision_recall_curve(y_test.ravel(), y_score.ravel())
average_precision["micro"] = average_precision_score(y_test, y_score, average="micro")
# Plot Precision-Recall curve for each class
plt.style.use('seaborn') #选择'seaborn'画布分格,使绘图美观一点
plt.clf()#clf 函数用于清除当前图像窗口
plt.plot(recall["micro"], precision["micro"],
label='micro-average Precision-recall curve (area = {0:0.2f})'.format(average_precision["micro"]))
for i in range(n_classes):
plt.plot(recall[i], precision[i],
label='Precision-recall curve of class {0} (area = {1:0.2f})'.format(i, average_precision[i]))
#xlim、ylim:分别设置X、Y轴的显示范围。
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
#设置横纵坐标标题
plt.xlabel('Recall', fontsize=16)
plt.ylabel('Precision',fontsize=16)
#设置P-R图的标题
plt.title('Extension of Precision-Recall curve to multi-class',fontsize=16)
plt.legend(loc="lower right")#legend 是用于设置图例的函数
plt.show()
CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)