【python机器学习100天—2022年】Day4-逻辑回归
大家好,我是ly甲烷😜,后端开发也有做算法的心呀💗 ,我们来学习python机器学习github有37.1k star的机器学习100天原项目地址https://github.com/Avik-Jain/100-Days-Of-ML-Code之前的机器学习100天有很多库或者函数已经不用了,还有刚入门机器学习可能很多函数或者设置搞不明白,所以,从python基础无缝到机器学习的教程来了。博主亲
大家好,我是ly甲烷😜,后端开发也有做算法的心呀💗 ,我们来学习python机器学习
github有37.1k star的机器学习100天原项目地址https://github.com/Avik-Jain/100-Days-Of-ML-Code
之前的机器学习100天有很多库或者函数已经不用了,还有刚入门机器学习可能很多函数或者设置搞不明白,
所以,从python基础无缝到机器学习的教程来了。博主亲自操作一遍过的记录,绝对细致。如果学不会可以评论区讨论,如果我懂,我会回复的。
今天是机器学习第一天——数据预处理 👇 👇 👇,前一天——数据预处理。
数据集
链接:https://pan.baidu.com/s/1Y2vZ5Rvn2PpRkj9XhnZrXQ?pwd=yyds
提取码:yyds
今日目标
数据集合包括人们的编号、性别、年龄、估算工资、和是否购买某个东西
通过逻辑回归模型训练数据,实现从人们的年龄和其估算工资来预测其是否会购买某个东西。
相关概念
什么是逻辑回归
简单来说,逻辑回归实际上是分类模型,常用于二分类即0、1分类
逻辑回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计
1. 数据预处理
# 第一步:数据预处理
# 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据集
dataset = pd.read_csv(r'E:\workspace\python_workspace\datasets\Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
Y = dataset.iloc[:, 4].values
# 将数据集分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25, random_state=0)
# 特征标准化
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
2.逻辑回归模型训练训练集
# 第二步:逻辑回归模型
# 逻辑回归模型训练训练集
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, Y_train)
3.预测结果
# 第三步:预测
Y_pred = classifier.predict(X_test)
4.评估结果
# 第四步:评估预测
# 生成混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(Y_test, Y_pred)
from matplotlib.colors import ListedColormap
# 4.1 训练集可视化
X_set,y_set=X_train,Y_train
x = np.arange(start=X_set[:,0].min()-1, stop=X_set[:, 0].max()+1, step=0.01)
y = np.arange(start=X_set[:,1].min()-1, stop=X_set[:,1].max()+1, step=0.01)
#把x,y绑定为网格的形式
X1,X2=np. meshgrid(x,y)
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(),X1.max())
plt.ylim(X2.min(),X2.max())
for i,j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set==j,0],X_set[y_set==j,1],
c = ListedColormap(('red', 'green'))(i), label=j)
plt. title(' LOGISTIC(Training set)')
plt. xlabel(' Age')
plt. ylabel(' Estimated Salary')
plt. legend()
plt. show()
#4.2 测试集可视化
X_set,y_set=X_test,Y_test
x = np.arange(start=X_set[:,0].min()-1, stop=X_set[:, 0].max()+1, step=0.01)
y = np.arange(start=X_set[:,1].min()-1, stop=X_set[:,1].max()+1, step=0.01)
#把x,y绑定为网格的形式
X1,X2=np. meshgrid(x,y)
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(),X1.max())
plt.ylim(X2.min(),X2.max())
for i,j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set==j,0],X_set[y_set==j,1],
c = ListedColormap(('red', 'green'))(i), label=j)
plt. title(' LOGISTIC(Test set)')
plt. xlabel(' Age')
plt. ylabel(' Estimated Salary')
plt. legend()
plt. show()
训练集可视化分类结果: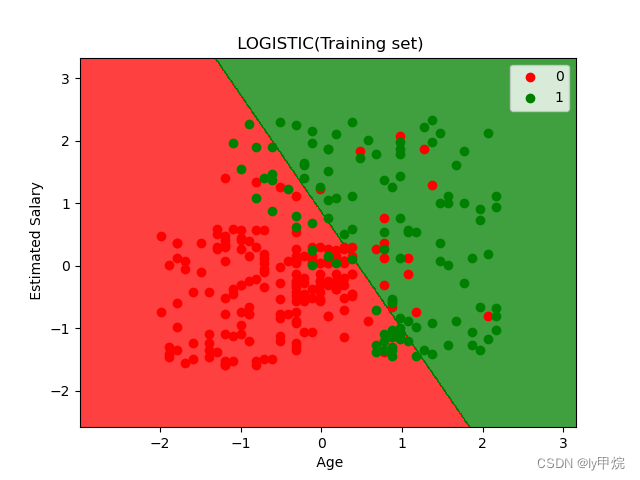
测试集分类可视化结果,可以看出多数分的还是比较准的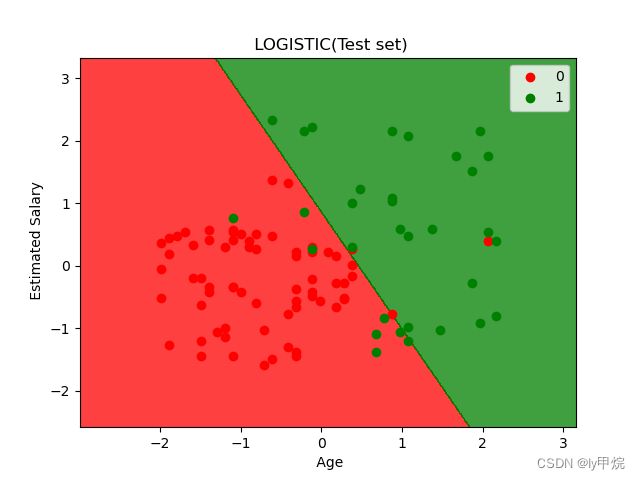
混淆矩阵
Confusion Matrix(混淆矩阵) 解释 https://blog.csdn.net/wowotuo/article/details/38262057
函数讲解
np.arange():函数返回一个有终点和起点的固定步长的排列,如[1,2,3,4,5],起点是1,终点是6,步长为1。
np.meshgrid(): 生成网格点坐标矩阵。numpy.meshgrid()理解
plt.contourf(): 用来画红绿两种结果的分界线, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape),这个是利用逻辑回归模型预测分界线。
.ravel(): 将多维数组降为一维数组。
T: 实现数组转置和轴对换。
.reshape: A.reshape(X1.shape)将A的类型重塑为X1的shape。
plt.xlim: 设置x坐标轴范围。
plt.ylim: 设置y坐标轴范围。
unque(): 是一个去重函数。
enumerate: 用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
今日总结:
逻辑回归模型进行分类预测。 有几个函数需要了解,第一次见可能比较陌生,大概了解一下,以后见多了熟悉了
今天就到这里啦,如果不懂,可以调试调试,看看变量是怎么变的,有不足和错误的地方欢迎大家指正👐
大家可以在评论区留下足迹👍 💬 ⭐️、留下遇到的问题哦。或者你也可以记录学习博客,留下你的博客地址
每天半小时,100天打卡挑战,让我们学会机器学习~💖

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)