机器学习入门研究(十四)-逻辑回归
目录概述Sigmoid函数损失函数优化损失对应的sklearn的API实例数据集特征总结概述分类模型,用于估计某种事物的可能性,常用于以下场景:广告点击率:是否被点击垃圾邮件:是否为垃圾邮件是否患病金融诈骗:是否是金融诈骗虚假账号:是否是虚假账号上述场景中的共同点:都是二分类问题,存在一个正例和一个反例。逻辑回归的原理就是将...
目录
概述
分类模型,用于估计某种事物的可能性,常用于以下场景:
广告点击率:是否被点击
垃圾邮件:是否为垃圾邮件
是否患病
金融诈骗:是否是金融诈骗
虚假账号:是否是虚假账号
上述场景中的共同点:都是二分类问题,存在一个正例和一个反例。
逻辑回归的原理就是将线性回归的输出作为Sigmoid函数的输入而构造的函数。
Sigmoid函数
又称为逻辑函数、激活函数,用公式表示如下:
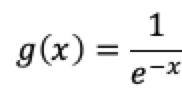
其函数如图:
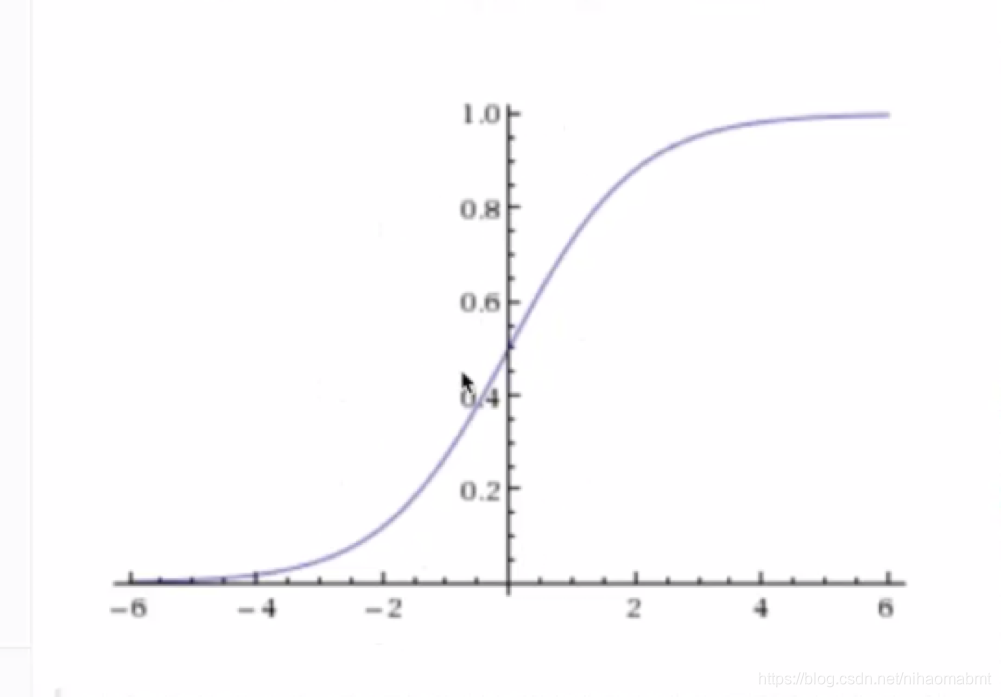
该函数就是一个s型曲线,取值范围为[0,1]之间。
逻辑回归就是将线性回归的输出作为Sigmoid函数的输入,
![]()
将线性回归的输出代入到上面的公式的x的位置,之后变形为:
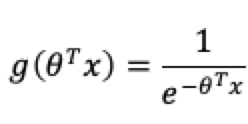
其中x为样本集,而就是我们要求解的权重。该函数的输出是[0,1]的概率值,默认阀值为0.5,而通过这个阀值就可以判断是哪个类别,并且默认的标记1为正例,另一个类别会标记为0,为反例。
损失函数
在线性回归中,通过求解损失函数的最小值来得到线性回归的偏置和权重,也就是求解预测值和真实值的平方和的最小值;但是对于逻辑回归来说,同样也是去求解损失函数的最小值得到Sigmoid函数中的权重和偏置,但是此时预测值已经是1和0,无法与真实值进行对比,所以这里引入对数似然损失:
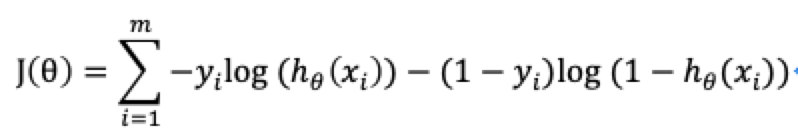
其中yi为真实值,![]() 为预测值。
为预测值。
当yi=1时,此时为正例,损失函数如图:
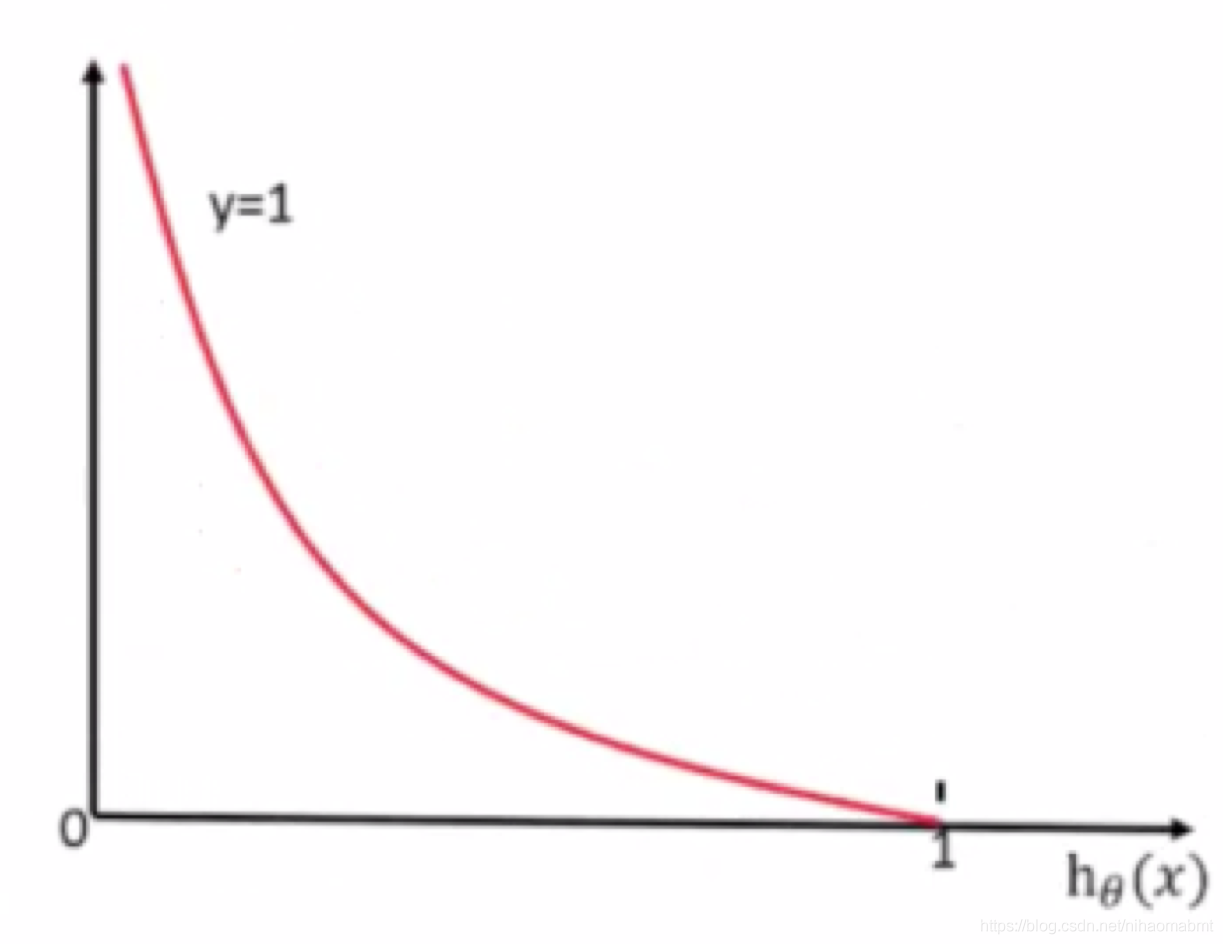
我们可以看到y越接近1的位置的时候,损失函数的值越接近于0
当yi=0时,此时为反例,损失函数如图:
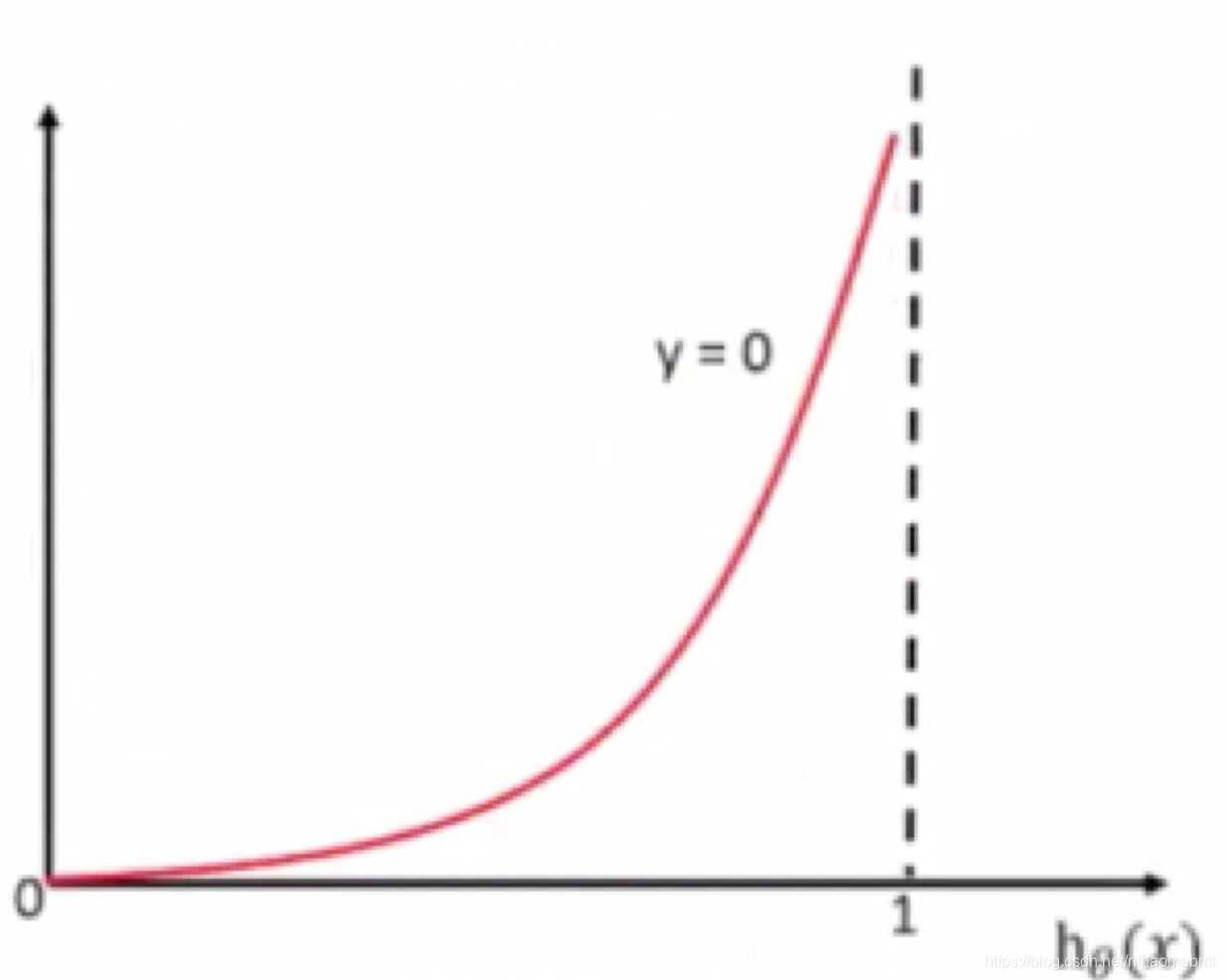
m同样可以看到y越接近于0的位置的时候,损失函数的值越接近于0
优化损失
和机器学习入门研究(十二)-线性回归一样,使用梯度下降优化算法,来减小损失函数的值,提升原本是1类别的概率,降低原本是0类别的概率。
对应的sklearn的API
LogisticRegression(self, penalty='l2', dual=False, tol=1e-4, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver='warn', max_iter=100,
multi_class='warn', verbose=0, warm_start=False, n_jobs=None,
l1_ratio=None):其中参数含义如下
| 参数 | 含义 |
| penalty | 正则化选择参数,可选值有l1、l2,默认为l2。一般l2就够了,如果L2正则化发现还是过拟合,即预测效果很差的化,可考虑l1。另外如果模型的特征非常多,希望一些不重要的特征系数为0,从而让模型稀疏化,也可采用l1。 与solver配合使用。 |
| dual | 默认为False,只适用于正则化l2的solver为liblinear的情况下。 通常样本数大于特征数的情况下,默认为False |
| tol | 迭代终止判断的误差范围,默认为1e-4 |
| C | 正则化系数 |
| fit_intercept | 是否存在截距,默认为true |
| intercept_scaling | 仅在solver为liblinear且fit_intercept为true的时候有效 |
| class_weight | 分类中各种类型的权重。可定义为class_weight={0:0.8,1:0.2},即类别为0的样本量为80%,1类别的样本量为20%。 主要作用在于: 第一种误分类的代价很高,比如是否为合法用户进行分类。通常做法是宁愿将合法用户判断为非合法用户,然后在人工判断。这样就可以适当提高非合法用户的权重 第二种是样本高度失衡,比如合法用户数据有10000条,而非法用户只有5条,如果不考虑权重,很有可能都被判断为合法用户,所以可以选择balanced,自动提高非法用户的样本的权重。 另外对于样本高度失衡,我们可以通过调整class_weight 来调整样本权重,另外还有一种在调用fit函数通过设置该函数的参数sample_weight来调整样本的权重。 |
| random_state | 随机状态 |
| solver | 与penalty配合使用。 如果penalty为l2,则该值有 "newton-cg":牛顿法家族的一种,利用损失函数的二阶导数矩阵即海森矩阵来迭代优化损失函数。 "lbfgs":拟牛顿法的一种,利用损失函数的二阶导数矩阵即海森矩阵来迭代优化损失函数。 sag:随机平均梯度下降 上述三者适用于较大数据集,支持one-vs-rest(OvS)和many-vs-many(MvM)两种多元逻辑回归。 如果是样本量非常大,比如>10万,sag是第一选择,但不能使用l1正则化。 前三者要求损失函数的一阶或者二阶连续导数 liblinear:开源的liblinear库,内部使用了坐标轴下降法来优化损失函数。适用于小数据集,只支持多元回归的OvR,不支持MvM
如果为l1,则只能取liblinear |
| max_iter | 最大迭代次数 |
| multi_class | 分类方式的选择 ovr:即one-vs-rest mulitmomial:即many-vs-many。 如果是二元逻辑回归,两者没有差别。主要差别在多元逻辑回归。 ovr:把多元逻辑回归看成二元逻辑回归。对于第K类的分类决策,把第K类的样本作为正例,其他除第K类的所有样本作为负例,得到第K类的分类模型。其他分类依次类推 MvM:如果模型有T类,每次在所有的T类样本里面选择出两类样本,记为T1和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。共进行T(T-1)/2次分类 |
| verbose | 日志冗长度。 0:不输出训练过程;1偶尔输出 |
| warm_start | 是否热启动。默认False True:则下次训练是以追加树的形式进行,重新使用上一次的调用作为初始化 |
| n_jobs | 并行数。默认为1 -1:跟CPU核数一致 |
| l1_ratio |
实例
癌症分类预测-是良性还是恶性
数据集特征
有699样本,共11列数据,第一列是检索id,其他的都是跟肿瘤有关的医学特征,最后一列就是肿瘤类型,其中里面有16个缺失值,已经用?标出。
数据集的地址为:
https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data
其中里面对应的字段说明为:
https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.names
我们通过juptyer可以看到数据结构如下:
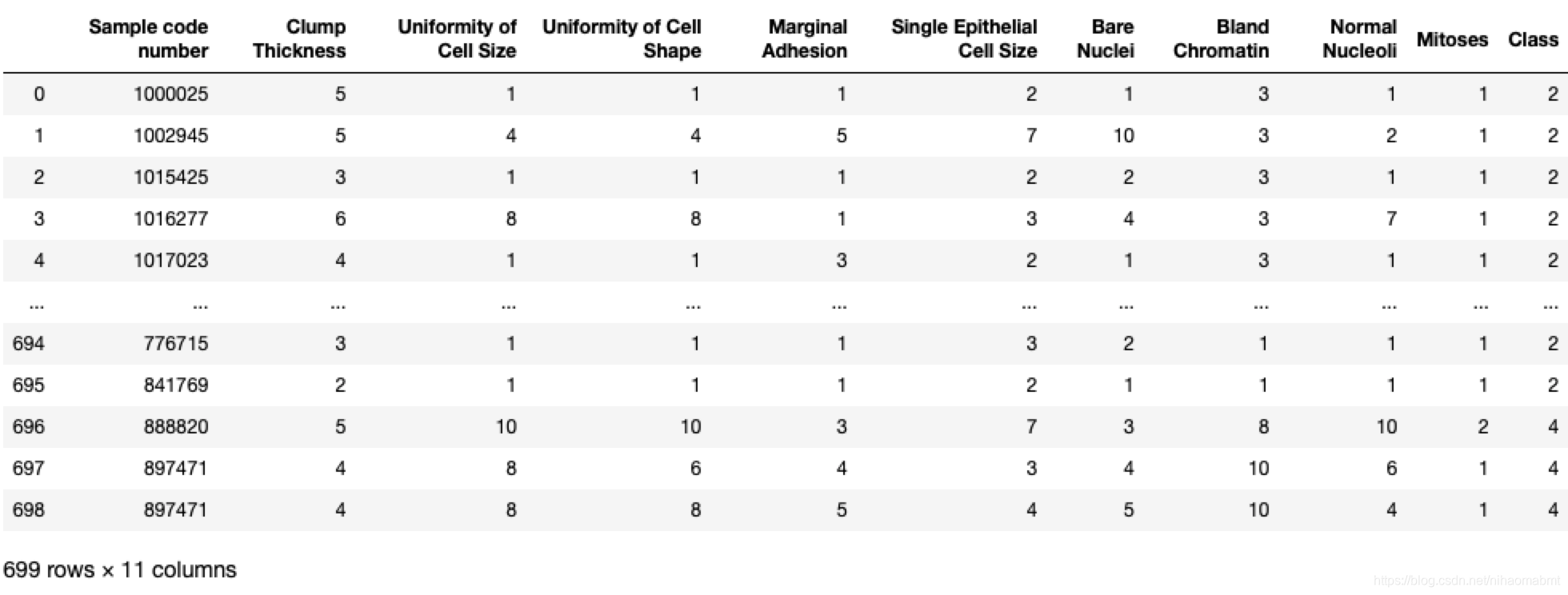
对于最后的分类结果中2表示良性,4表示恶性。
我们看下代码如下:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LogisticRegression
import pandas as pd
import numpy as np
def regression():
# 1)获取数据集
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data"
column_names = ["Sample code number", "Clump Thickness ", "Uniformity of Cell Size ", "Uniformity of Cell Shape"
, "Marginal Adhesion", "Single Epithelial Cell Size", "Bare Nuclei", "Bland Chromatin", "Normal Nucleoli",
"Mitoses", "Class"]
data = pd.read_csv(path, names=column_names)
# 2)对数据进行缺失值处理,并将?替换成NAN
data = data.replace(to_replace="?",value=np.nan)
data.dropna(inplace=True)
# 3)划分数据集
#除去最后一列是目标值,其他的列都是特征值
x = data.iloc[:,1:-1]
y = data["Class"]
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4)进行标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 5)预估器
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 6)进行预测
y_predict = estimator.predict(x_test)
#print("预测值:", y_predict)
print("真实值:", y_test==y_predict)
print("逻辑回归模型的参数为 w :", estimator.coef_)
print("逻辑回归模型的参数为 b:", estimator.intercept_)
# 7)模型评估
error = mean_squared_error(y_test, y_predict)
print("逻辑回归 的误差值:", error)
return看下输出结果如下:
逻辑回归模型的参数为 w : [[1.166673 0.1206053 0.72963858 0.60897593 0.10861572 1.47922335
0.7462081 0.79426579 0.87710322]]
逻辑回归模型的参数为 b: [-0.97797973]
逻辑回归 的误差值: 0.0935672514619883我们看到有几个特征值就会输出几个特征系数,那么这个误差值已经很小了。
总结
2019年快要结束的时候,开始学起机器学习的相关内容,感觉还挺好玩的,由于中间在忙项目招标的事情,中间有一段时间没有时间去看,赶在放假之前把这个写了好几天的文档总结完,等着春节回来之后,一定尽量挤时间去学习下。
加油!!!

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)