datawhale 11月学习——水很深的深度学习:深度学习概述和数学基础
概述本节复习和回顾了深度学习的概念,了解了深度学习起源和发展的主要阶段,了解了一些重要的研究机构和著名的科学家。回顾并将深度学习的一些数学基础串到了一起,主要涵盖四个部分:矩阵论,概率统计,信息论,和最优化估计。目录概述1 深度学习概述1.1 人工智能、机器学习和深度学习1.2 起源与发展1.3 重要的研究机构和著名科学家2 深度学习的数学基础2.1 矩阵论2.2 概率统计2.3 信息论2.4 最
概述
本节复习和回顾了深度学习的概念,了解了深度学习起源和发展的主要阶段,了解了一些重要的研究机构和著名的科学家。
回顾并将深度学习的一些数学基础串到了一起,主要涵盖四个部分:矩阵论,概率统计,信息论,和最优化估计。
目录
1 深度学习概述
1.1 人工智能、机器学习和深度学习
本部分内容与先前的博文李宏毅深度学习:机器学习介绍内容接近,可参考先前博文,此处做简单回顾。
人工智能,机器学习和深度学习的关系如下图所示:
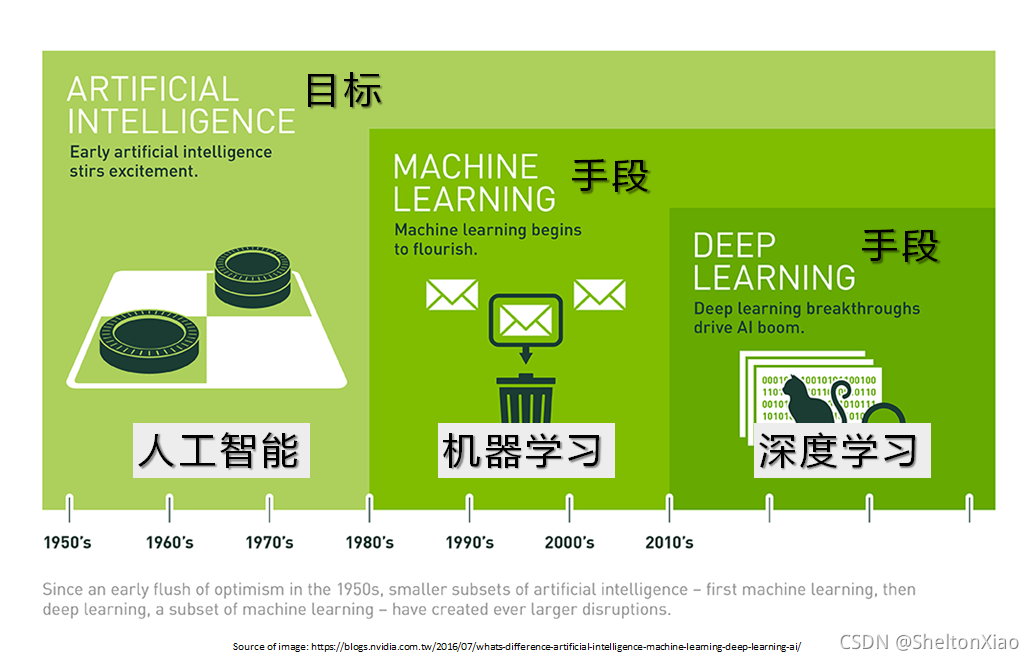
其中,人工智能可以分为三类:
强人工智能:认为有可能制造出真正能推理和解决问题的智能机器,这样的机器被认为是有自主意识的
弱人工智能:认为不可能制造出能真正进行推理和解决问题的智能 机器,这些机器只不过看起来像是智能的,但是并不真正拥有智能, 也不会有自主意识
超级人工智能:机器的智能彻底超过了人类,“奇点”2050年到来?
强人工智能应能完成图灵测试,目前的大部分人工智能处于弱人工智能状态。
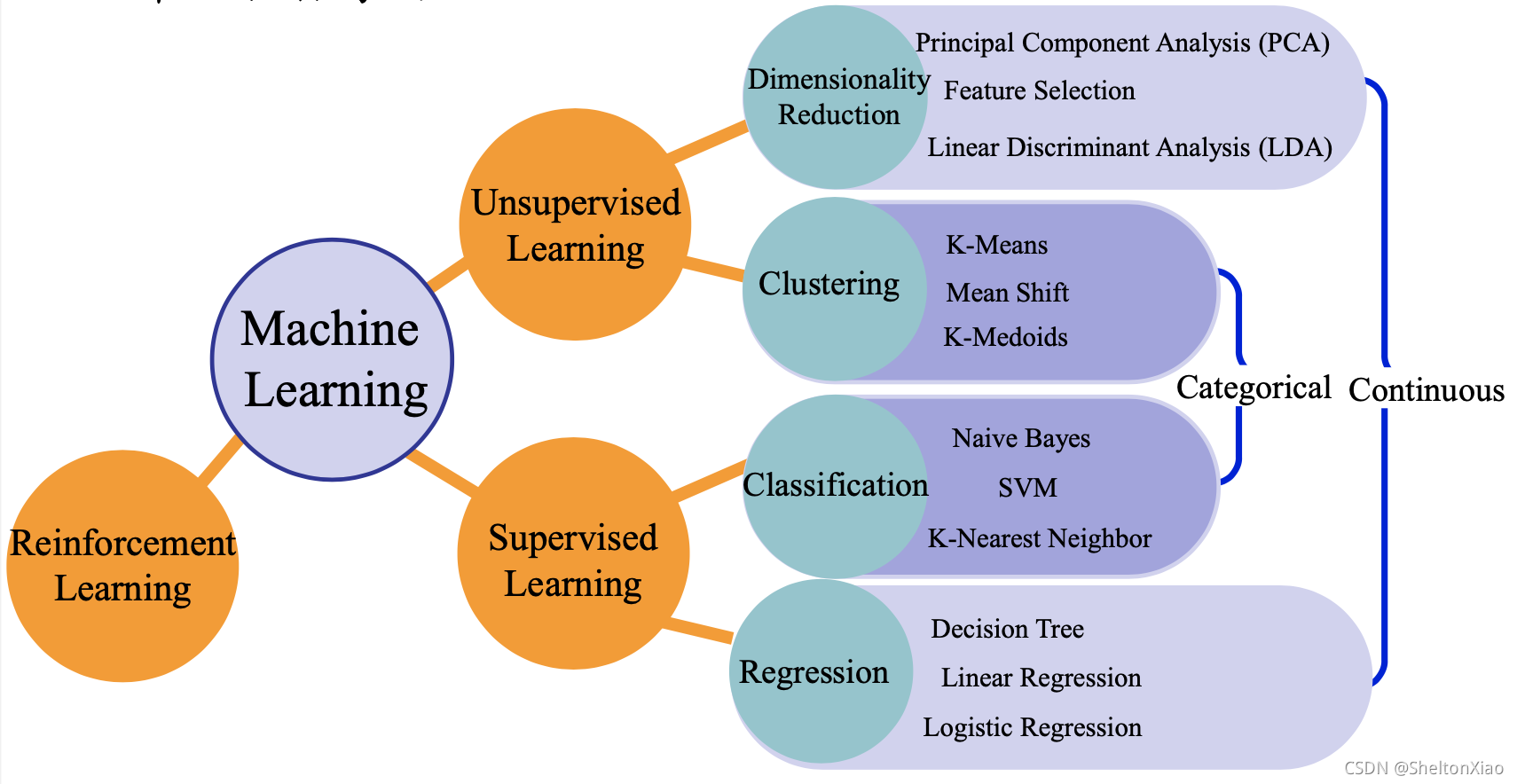
机器学习可以分为以下几类:
- 监督学习
- 无监督学习
- 强化学习
- 迁移学习
当然,还有半监督学习。教程里的这张图还区分了目标连续型任务和离散型任务的区别,并小结了对应的算法。
1.2 起源与发展
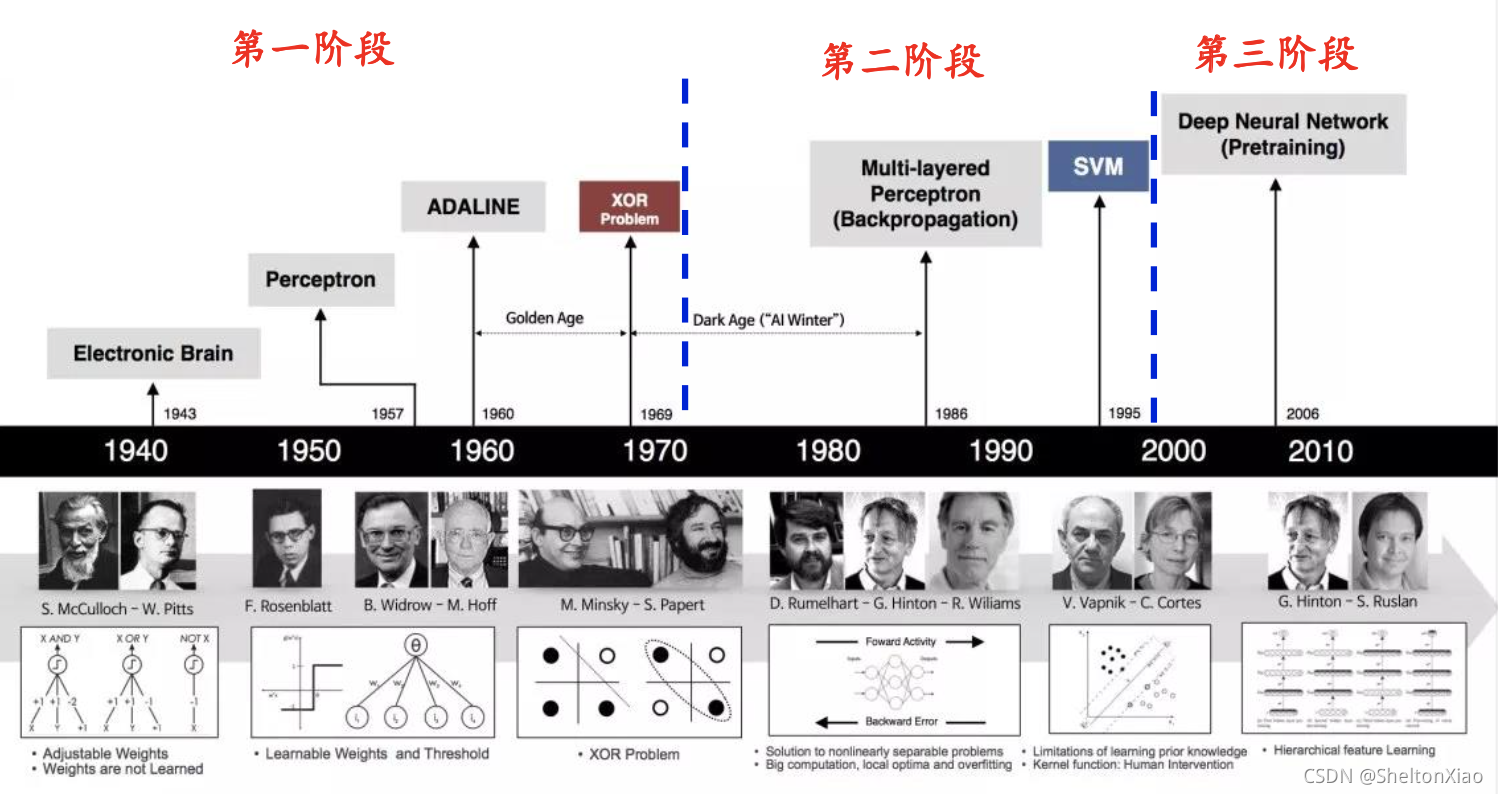
分为三大阶段
- 第一阶段,属于概念阶段,很多概念在发展,但是无法进行规模计算,很多问题无法解决;
- 第二阶段,概念已经发展到了可以解决问题的程度,同时相对应的计算机制(反向传播)也开始发展;
- 第三阶段,大规模发展阶段,开始越来越多地用于多种学科的复杂任务,比如语音处理,图像识别,甚至围棋竞技等任务。
1.3 重要的研究机构和著名科学家
了解这些可以帮助我们更好地把握学科脉络。
深度学习研究机构包括:
- Machine Learning at University of Toronto
- Deepmind at Google:提出AlphaGo的
- AI research at Facebook
- 清华大学AI研究院
- 中国科学院自动化所
- 中国科学院数学与系统科学研究院
- Tencent AI Lab
- 华为诺亚方舟实验室
- 阿里达摩院
等
深度学习的知名科学家包括:
- Geoffrey Hinton:深度学习之父
- Yann LeCun:卷积神经网路之父
- Yoshua Bengio
- 吴恩达(Andrew Ng)
等
2 深度学习的数学基础
主要涵盖四个部分:矩阵论,概率统计,信息论,和最优化估计。
2.1 矩阵论
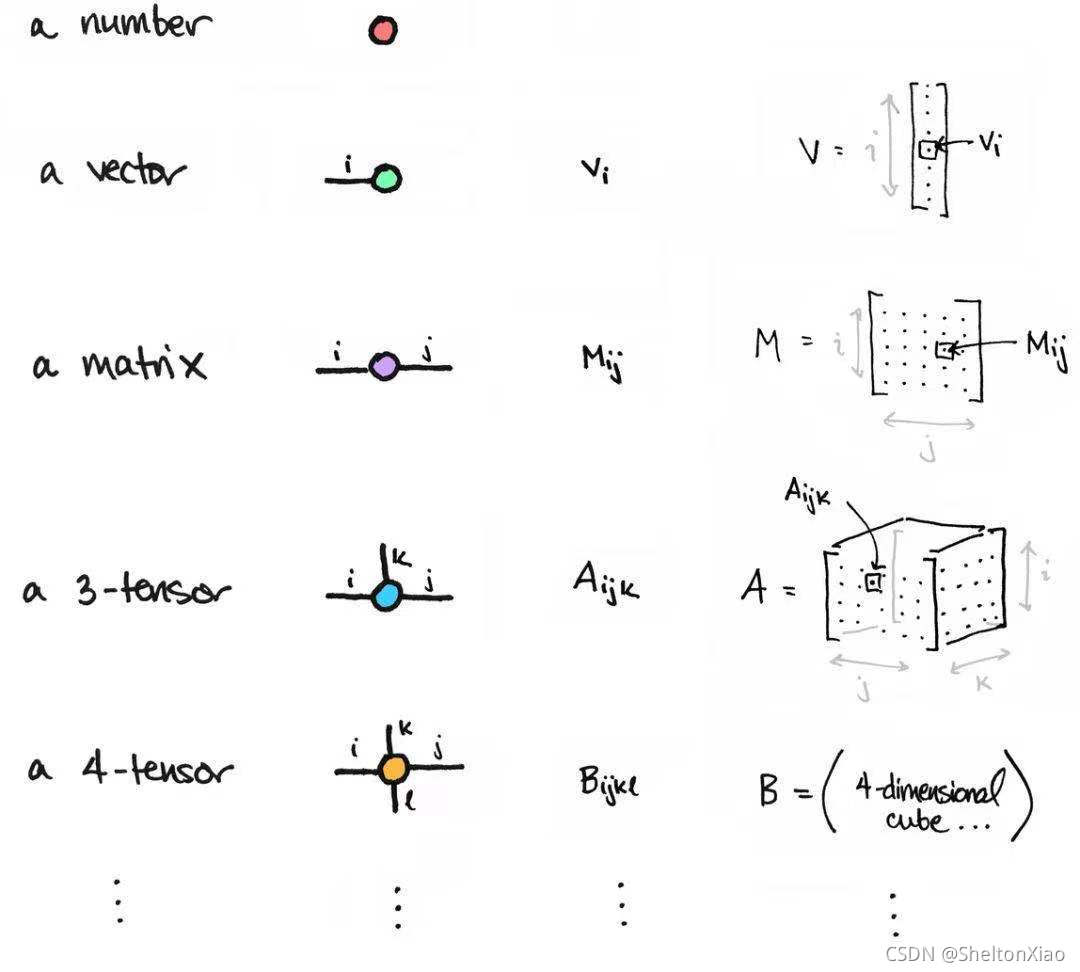
需要了解的知识包括矩阵的基本概念(张量,矩阵的秩,矩阵的逆,广义逆矩阵)以及矩阵的分解(特征分解,奇异值分解)等。
其中大部分的知识在线性代数中学习过,主要涉及的难点在于张量。

这个人很好地讲解了张量与三维向量的不同,视频地址
2.2 概率统计
常见的随机变量的概率分布如下
离散型随机变量

连续型随机变量
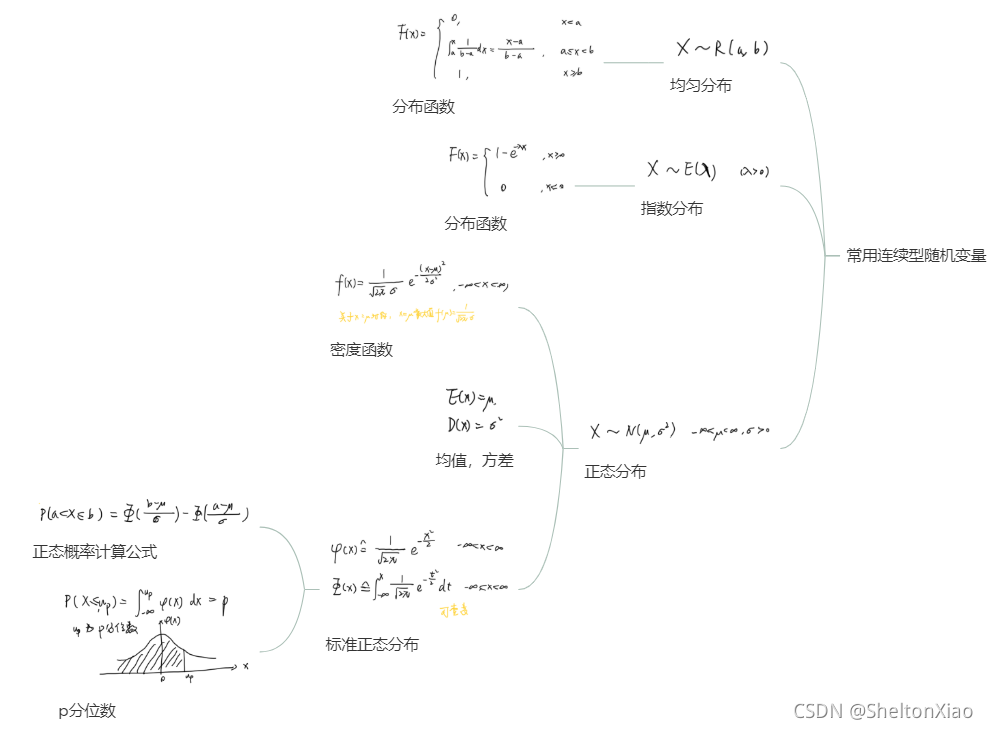
多个变量时,概率分布会有不同
-
条件概率

-
联合概率
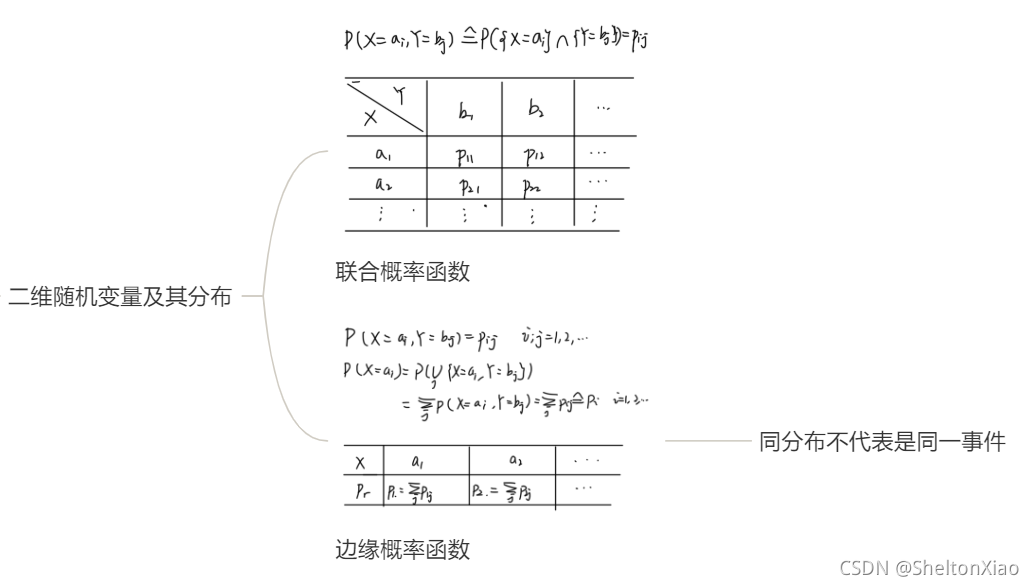
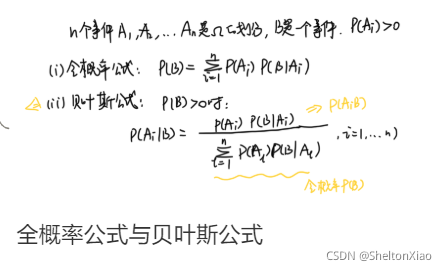
-
先验概率
-
后验概率
-
全概率公式
-
贝叶斯公式
常用统计量为
-
方差

-
协方差

2.3 信息论
这一部分可以参考之前的笔记树模型与集成学习:决策树中关于信息论的部分。
最基础的概念是熵,它是样本集合纯度的一种指标,在他的基础上发展出了联合熵、条件熵以及互信息。
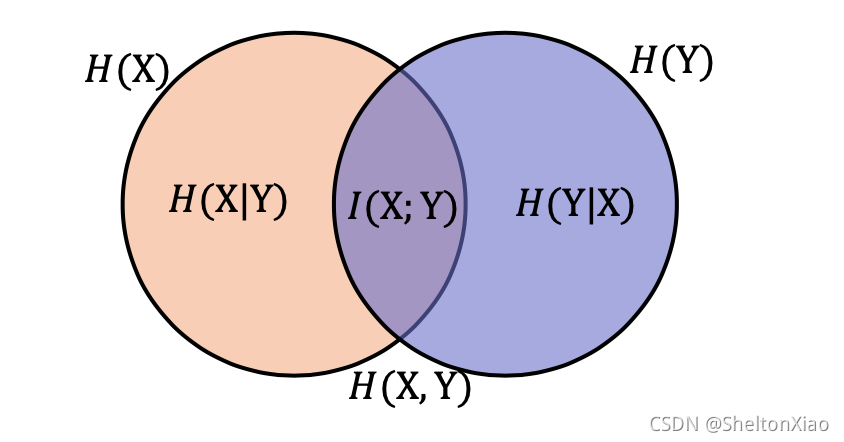
此外还有相对熵(KL散度)和交叉熵(经常作为损失函数,一般用来求目标和预测值之间的差距)
2.4 最优化估计
最基础的是最小二乘估计。
最小二乘估计又称最小平方法,是一种数学优化方法。它通过最小化误差的平方和寻找数据的最佳函数匹配。最小二乘法经常应用于回归问题,可以方便地求得未知参数,比如曲线拟合、最小化能量或者最大化熵等问题。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)