深度学习基础篇之循环神经网络(RNN)
前面我们讲了DNN,以及DNN的特例CNN的模型及其前向反向传播算法,这些算法都是前向反馈的,模型的输出和模型本身没有关联。今天我们就讨论另一类模型间有反馈的神经网络:循环神经网络(Recurrent Neural Networks,以下简称RNN),它广泛的用于自然语言处理中的语音识别、手写识别及机器翻译等。
前面我们讲了DNN,以及DNN的特例CNN的模型及其前向反向传播算法,这些算法都是前向反馈的,模型的输出和模型本身没有关联。今天我们就讨论另一类模型间有反馈的神经网络:循环神经网络(Recurrent Neural Networks,以下简称RNN),它广泛的用于自然语言处理中的语音识别、手写识别及机器翻译等。
1、RNN概述
在前面的DNN和CNN中,训练样本的输入和输出是比较确定的。但是有一类问题DNN和CNN不好解决,就是训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音、一段段长短不一的手写文字。这些序列比较长,而且长度不一,比较难直接的拆分一个个独立的样本来通过DNN/CNN进行训练。
对于这类问题,RNN会比较擅长。那么RNN是怎么做到的呢?RNN假设我们的样本是基于序列的,比如是从序列索引 1 1 1到序列索引 n n n的。对于这其中的任意序列索引号 t t t,它对应的输入是样本序列中的 x ( t ) x^{(t)} x(t)。模型在序列索引 t t t位置的隐藏状态 h ( t ) h^{(t)} h(t),由 x ( t ) x^{(t)} x(t)和在 t − 1 t-1 t−1位置的隐藏状态 h ( t − 1 ) h^{(t-1)} h(t−1)共同决定。在任意序列索引号 t t t,我们对应的模型输出是 o ( t ) o^{(t)} o(t)。通过预测输出 o ( t ) o^{(t)} o(t)和训练序列真实输出 y ( t ) y^{(t)} y(t)、以及损失函数 L ( t ) L^{(t)} L(t),我们就可以用与DNN类似的方法训练模型,然后预测测试序列中一些未知的输出。
下面我们看看RNN模型的结构
2、RNN模型
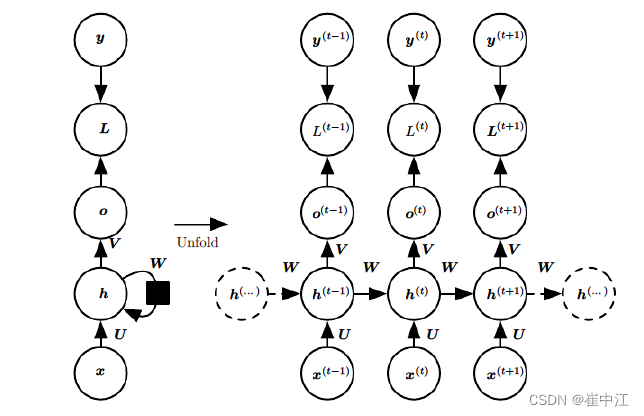
RNN模型有很多的变种,这里介绍最主流的RNN模型结构如下:
上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,就是上图中右边的部分,下面我们重点观察右边部分的图。
这幅图描述了在序列索引号时间
t
t
t附近RNN的模型,其中:
- x ( t ) x^{(t)} x(t)代表在序列索引 t t t时训练样本的输入,同样的, x ( t − 1 ) x^{(t-1)} x(t−1)和 x ( t + 1 ) x^{(t+1)} x(t+1)代表在序列索引号 t − 1 t-1 t−1和 t + 1 t+1 t+1时训练样本的输入。
- h ( t ) h^{(t)} h(t)代表在序列索引号 t t t时模型的隐藏状态, h ( t ) h^{(t)} h(t)由 x ( t ) x^{(t)} x(t)和 h ( t − 1 ) h^{(t-1)} h(t−1)共同决定。
- o ( t ) o^{(t)} o(t)代表在序列索引号 t t t时模型的输出, o ( t ) o^{(t)} o(t)只由模型当前的隐藏状态 h ( t ) h^{(t)} h(t)决定。
- L ( t ) L^{(t)} L(t)代表在序列索引号 t t t时模型的损失函数。
- y ( t ) y^{(t)} y(t)代表在序列索引号 t t t时训练样本序列的真实输出。
- U , W , V U,W,V U,W,V这三个矩阵是我们模型的参数,它在整个RNN模型中是共享的,这点和DNN不相同。也正是因为共享,体现了RNN模型的“循环反馈”思想。
3、RNN前向传播算法
有了上面的模型,RNN的前向传播算法就可以推导出来了。
对于任意一个序列索引号
t
t
t,隐藏状态
h
(
t
)
h^{(t)}
h(t)由
x
(
t
)
x^{(t)}
x(t)和
h
(
t
−
1
)
h^{(t-1)}
h(t−1)得到:
h
(
t
)
=
σ
(
z
(
t
)
)
=
σ
(
U
x
t
+
W
h
(
t
−
1
)
+
b
)
h^{(t)} = \sigma(z^{(t)}) = \sigma(Ux^{{t}} + Wh^{(t-1)} + b)
h(t)=σ(z(t))=σ(Uxt+Wh(t−1)+b) 其中
σ
\sigma
σ是RNN的激活函数,一般为
t
a
n
h
tanh
tanh,
b
b
b为线性关系的偏倚。
序列索引号
t
t
t时模型的输出
o
(
t
)
o^{(t)}
o(t)的表达式如下:
o
(
t
)
=
V
h
(
t
)
+
c
o^{(t)} = Vh^{(t)} + c
o(t)=Vh(t)+c 最终的预测输出为:
y
^
=
σ
(
o
(
t
)
)
\hat y = \sigma(o^{(t)})
y^=σ(o(t))
通常由于RNN是识别类的分类模型,所以上面的激活函数一般是softmax,通过损失函数
L
(
t
)
L^{(t)}
L(t),比如对数似然损失函数,我们可以量化模型在当前位置的损失,即
y
^
(
t
)
\hat y^{(t)}
y^(t)和
y
(
t
)
y^{(t)}
y(t)的差异。
4、RNN结构的缺陷
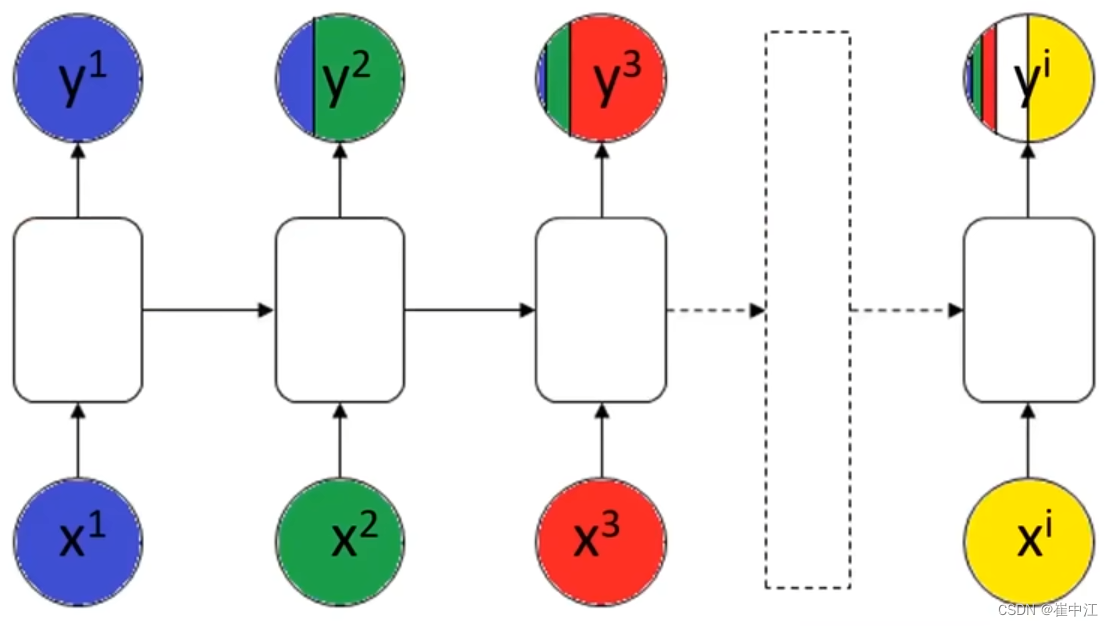
普通的RNN结构在处理长序列时会遇到一些问题,如序列的前部信息在传递至后面的时候,信息权重下降,导致重要信息的丢失。
The student, who got A+ in the exam, ____excellent.
The students, who got A+ in the exam, ____excellent.
当RNN模型在处理上述文本时,可能就会因为没注意到student是单数还是复数,导致was和were填错。信息下降的过程如下图所示:
普通RNN结构的缺点总结如下:
- 前部序列信息在传递到后部时,信息权重下降,导致重要信息丢失。
- 求解过程中梯度消失(也是由于序列太长所致)。
所以要对RNN的结构进行升级,下一节的LSTM就是为了解决RNN的上述问题而提出的。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)