TensorFlow、Keras 和 Python 构建神经网络分析鸢尾花iris数据集|代码数据分享
原文链接:http://tecdat.cn/?p=30305鸢尾花iris数据集以及MNIST数据集可能是模式识别文献中最著名的数据集之一(点击文末“阅读原文”获取完整代码数据)。任务描述这是机器学习分类问题的“Hello World”示例。它由罗纳德·费舍尔于 1936 年首次推出。他是英国统计学家和植物学家,他在本文中使用了这个例子 在分类学问题中使用多重测量,这在今天经常被引用。数据集(查.
原文链接:http://tecdat.cn/?p=30305
鸢尾花iris数据集以及MNIST数据集可能是模式识别文献中最著名的数据集之一(点击文末“阅读原文”获取完整代码数据)。
任务描述
这是机器学习分类问题的“Hello World”示例。它由罗纳德·费舍尔于 1936 年首次推出。他是英国统计学家和植物学家,他在本文中使用了这个例子 在分类学问题中使用多重测量, 这在今天经常被引用。数据集(查看文末了解数据、代码免费获取方式)包含 3 个类,每个类 50 个实例。
相关视频
每类都指一种鸢尾植物:鸢尾、弗吉尼亚鸢尾和花色鸢尾。 **第一类与其他两个是线性可分离的,但后两个彼此之间不是线性可分离的。每条记录有五个属性:
萼片长度(厘米)
萼片宽度(厘米)
花瓣长度(厘米)
花瓣宽度(厘米)
类(鸢尾、弗吉尼亚鸢尾 、 杂色鸢尾)
我们将要创建的神经网络的目标是根据其他属性预测鸢尾花的类别。为了解决这个问题,我们将定义步骤:
数据的分析和预处理
构建和训练模型
评估模型
做出新的预测
算法实现步骤
1 数据分析与预处理
数据分析本身就是一个主题。在这里,我们不会深入到特征工程和分析,但我们将观察一些基本步骤:
单变量分析 – 分析每个特征的类型和性质。
缺失数据处理 – 检测缺失数据并制定策略。
相关性分析 – 比较彼此之间的特征。
拆分数据 – 因为我们有一组信息,所以我们需要制作一组单独的数据来训练神经网络和一组数据来评估神经网络。
使用我们在此分析过程中收集的信息,我们可以在创建模型本身期间采取适当的操作。首先,我们导入数据:
COLUMN_NAMES = [
'Sepal
data = pd.read_csv('iris_data.csv', names=COLUMN_NAMES, header=0)
data.head()如您所见,我们使用 Pandas 库,我们还打印出前五行数据。这是它的样子:
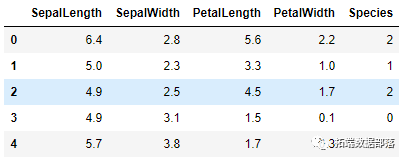
完成此操作后,我们想看看每个功能的性质是什么 。为此,我们也可以使用熊猫:
data.dtypes输出如下所示:

正如我们所看到的,物种或输出的类型为 int64。但是,我们知道这不是我们想要的。我们希望此功能是一个分类变量。这意味着我们需要稍微修改一下这些数据,再次使用 Pandas:
data['Species'ype("category")
data.dtypes完成此操作后,我们检查数据集中是否缺少数据。这是使用此函数完成的:
print(data.i).sum())此调用的输出为:

丢失数据可能是我们的神经网络的一个问题。如果我们的数据集中缺少数据,我们需要定义一个如何处理它的策略。一些方法是将缺失值替换为要素的平均值或其最大值。
但是,没有灵丹妙药,有时不同的策略比其他策略提供更好的结果。好的,进入相关性分析。在此步骤中,我们将检查功能如何相互关联。使用Pandas和Seaborn模块,我们能够获得一个图像,该图像显示了某些特征之间依赖级别的矩阵 - 相关矩阵:
c
fig.set_size_inches(20,10)
sn.heatmap(corrMatt, mask=mask,vmax=.8, square=True,annot=True)该矩阵如下所示:
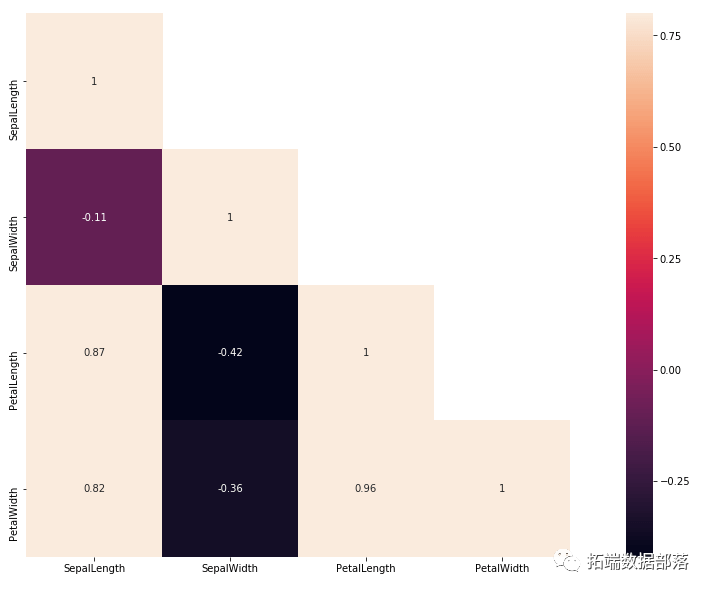
我们想使用这个相关矩阵找到 Spices 和一些特征之间的关系。如您所见,这些值介于 -1 和 1 之间。我们的目标是值接近 1 或 -1 的那些,这意味着这些功能没有太多共同点, 即。对彼此的影响太大。
点击标题查阅往期内容

【视频】CNN(卷积神经网络)模型以及R语言实现回归数据分析

左右滑动查看更多
01
02
03
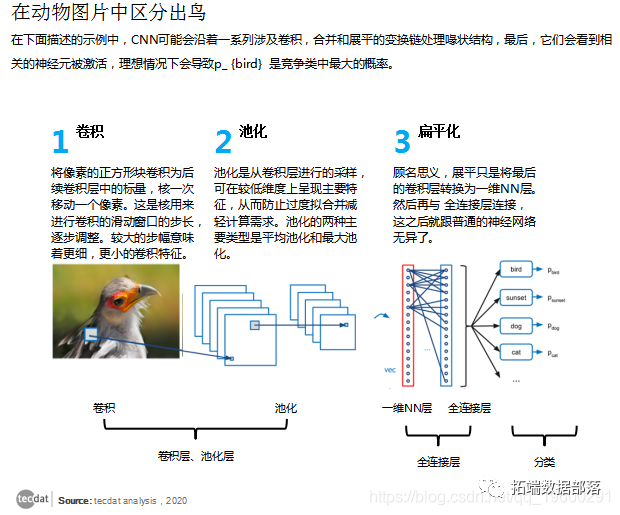
04
如果我们遇到这种情况,建议只为模型提供其中一个特征。这样,我们将避免我们的模型给出过于乐观(或完全错误)的预测的情况。但是,在这个数据集中,我们几乎没有信息,所以如果我们删除所有依赖项。
最后,让我们将数据拆分为训练集和测试集。因为客户通常会给我们一大块数据,所以我们需要留下一些数据进行测试。通常,这个比例是80:20。在本文中,我们将使用 70:30。为此,我们使用SciKit Learn库中的函数:
output_data ies",axis=1)
X_train, X_test, y_train, y_test = train_test_split(input_data, output_data, test_size=0.3, random_state=42)最后,我们有四个变量,其中包含用于训练和测试的输入数据,以及用于训练和测试的输出数据。我们现在可以构建我们的模型。
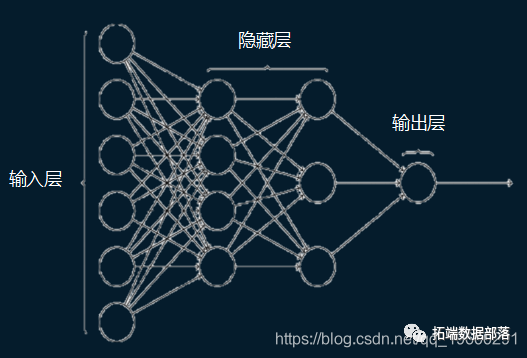
2 构建和训练神经网络
我们需要一个非常简单的神经网络来进行这种分类。在这里,我们使用模型子类化方法,但您也可以尝试其他方法。以下是 IrisClassifier 类的外观:
class IrisClassifier(Model):
def __ini0, activation='relu')
self.layer2 = Dense(10, activation='relu')
self.outputLayer = Dense(3, activation='softmax')
def call(self, x):
x = self.layer1(x)
x = self.layer2(x)
return
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='categorical_crossentropy',
metrics=['accuracy'])它是小型神经网络,具有两层 10 个神经元。最后一层有3个神经元,因为有3类鸢尾花。此外,在最后一层,激活函数使用的是softmax。
这意味着我们将以概率的形式获得输出。让我们训练这个神经网络。为此,我们使用 fit 方法并传递准备好的训练数据:
model.fit(X_train, y_train, epochs=300, batch_size=10)epoch 的数量定义了整个训练集将通过网络传递多少时间。这可以持续几分钟,输出如下所示:
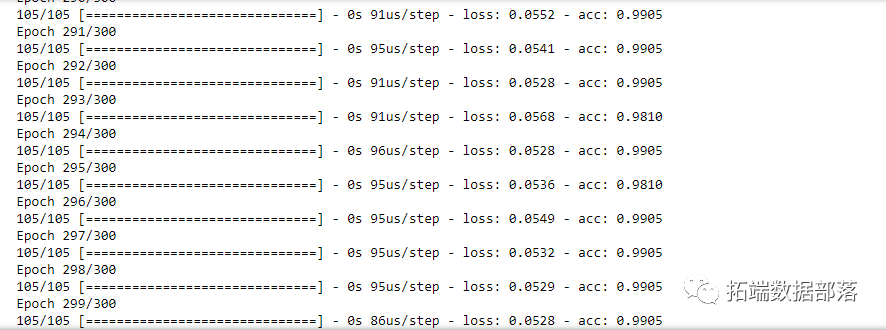
我们完成了。我们创建了一个模型并对其进行了训练。现在,我们必须对其进行评估,看看我们是否有好的结果。
实验结果
3 评估和新预测
评估是通过调用评估 方法完成的。我们向其提供测试数据,并为每个样本运行预测并将其与实际结果进行比较:
scores = mode%" % (scores[1]*100))在这种特殊情况下,我们得到了95.56%的准确率:
45/45 [==============================] - 0s 756us/step
Accuracy: 95.56%最后,让我们得到一些预测:
prediction = mme({'IRIS1':prediction[:,0],'IRIS2':prediction[:,1], 'IRIS3':prediction[:,2]})
prediction1.round(decimals=4).head()以下是我们与实际结果进行比较的结果:
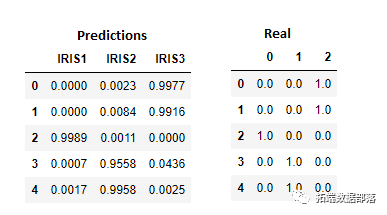
如果我们使用其他具有真实数据的数据集,这些好的结果将是可疑的。我们可以怀疑发生了“过度拟合”。但是,在这个简单的数据集上,我们将接受这些结果作为良好的结果。
TensorFlow vs PyTorch
TensorFlow/Keras和PyTorch是最流行的深度学习框架。一般来说,区别在于速度(使用 PyTorch 训练模型的速度更快)和 PyTorch 感觉。PyTorch也是纯粹的面向对象的,而使用TensorFlow,你可以选择。此外,TensorFlow在行业中占据主导地位,而PyTorch在研究中很受欢迎。
结论
神经网络已经存在了很长时间,几乎所有重要概念都可以追溯到 1970 年代或 1980 年代。阻止整个领域发展的问题是,当时我们没有强大的计算机和GPU来运行这些类型的过程。现在,我们不仅可以做到这一点,而且谷歌通过公开提供这个伟大的工具——TensorFlow,使神经网络变得流行起来。
数据、代码获取
在公众号后台回复“鸢尾花数据”,可免费获取完整数据、代码。

本文中分析的代码、数据分享到会员群,扫描下面二维码即可加群!


点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《使用TENSORFLOW、KERAS 和 PYTHON 构建神经网络分析鸢尾花IRIS数据集》。
点击标题查阅往期内容
【视频】CNN(卷积神经网络)模型以及R语言实现回归数据分析
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
深度学习实现自编码器Autoencoder神经网络异常检测心电图ECG时间序列
Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类

![]()


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)