自然语言处理笔记
2020自然语言处理语⾔是⼀种由三部分组成的符号交流系统:记号,意义和连接两者的符码。由组合语法规则制约、旨在传达语义的记号形式系统。自然语言:⼈类语⾔,通常是指一种自然地随文化演化的语言。汉语、英语、法语、西班牙语、葡萄牙文、日语、韩语、意大利文、德文为自然语言的例子。自然语言处理利⽤计算机为⼯具对⾃然语⾔进⾏各种加⼯处理、信息提取及应⽤的技术。自然语言理解:强调对语⾔含义和意图的深层次解释计算
2020自然语言处理
语⾔
是⼀种由三部分组成的符号交流系统:记号,意义和连接两者的符码。
由组合语法规则制约、旨在传达语义的记号形式系统。
-
自然语言:⼈类语⾔,通常是指一种自然地随文化演化的语言。汉语、英语、法语、西班牙语、葡萄牙文、日语、韩语、意大利文、德文为自然语言的例子。
-
自然语言处理
- 利⽤计算机为⼯具对⾃然语⾔进⾏各种加⼯处理、信息提取及应⽤的技术。
- 自然语言理解:强调对语⾔含义和意图的深层次解释
- 计算语⾔学:强调可计算的语⾔理论
自然语言处理的难点
- 歧义处理
- 语言知识的表示、获取和运用
- 成语和惯用型的处理
- 对语言的灵活性和动态性的处理
- 灵活性:同一个意图的不同表达,甚至包含错误的语法等
- 动态性:语言在不断的变化,如:新词等
- 对常识等与语言无关的知识的利用和处理
汉语处理的难点
- 缺乏计算语言学的句法/语义理论,大都借用基于西方语言的句法/语义理论
- 资源(语料库)缺乏
- 词法分析:词之间没有分隔符,词性标注没有词形变化
- 句法分析:主动词识别难,词法分类与句法功能对应差
- 语义分析:句法结构与句义对应差
- 时态确定困难
汉语分词
分词是指根据某个分词规范,把一个“字”串划分成“词”串。
切分歧义
- 交集型歧义:自主-和-平等,战争-与-和平-等问题
- 组合型歧义:他-骑-在-马-上,他-马上-过来
- 混合型歧义:今晚得-到达-南京,得到-达克宁-了,我得-到-达克宁-公司-去
分词方法

分词带来的问题
丢失信息、错误的分词、不同分词规范之间的兼容性
机器翻译
基于规则的机器翻译
由语⾔学⽅⾯的专家进⾏规则的制订。
模型更新需要专家进⾏(制定新的规则):
- 保证与原先规则兼容
- 不引⼊新的错误
缺点:需要语⾔学家⼤量的⼯作;维护难度⼤;翻译规则 容易发⽣冲突。
基于实例的机器翻译
从语料库中学习翻译实例。
- 查找接近的翻译实例,并进⾏逐词替换进⾏翻译
- 利⽤类⽐思想analogy,避免复杂的结构分析
统计机器翻译
- 可以⼀定程度上从数据中⾃动挖掘翻译知识
- 流程相对复杂,其中各个部分都不断被改进和优化
- 翻译性能遇到瓶颈,难以⼤幅度提升
神经网络机器翻译
语言模型
N-Gram
Pr ( X ) = ∏ i Pr [ X i ∣ X i − 1 ] \Pr(X)=\prod_i\Pr[X_i|X_{i-1}] Pr(X)=i∏Pr[Xi∣Xi−1]
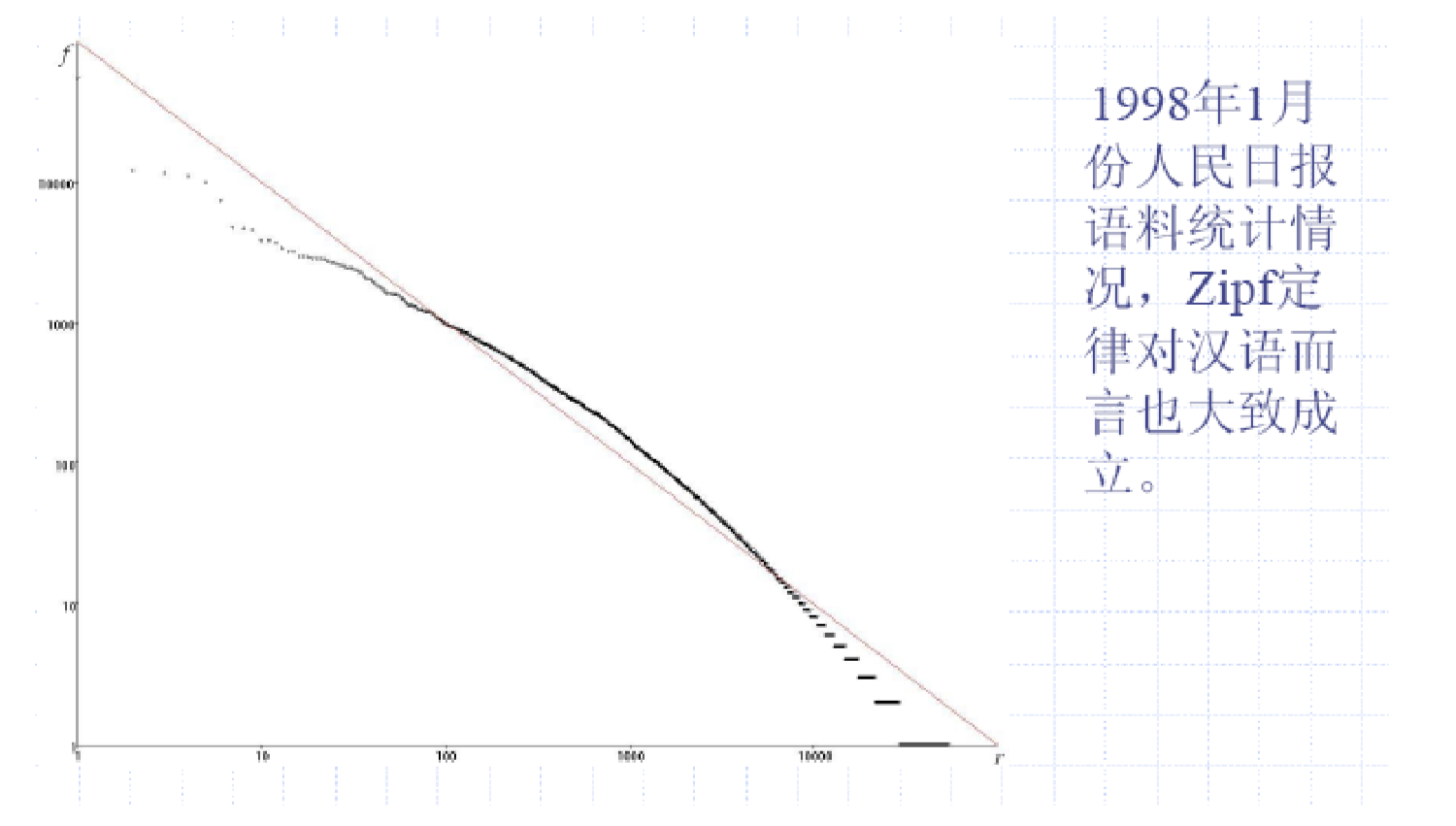
满足Zipf法则, f r = c fr=c fr=c,即词频和排位的乘积为定值,词频和排位成反比。
- 大部分词都是稀有的
平滑方法
- add counts: P = p + δ ∑ ( p + δ ) P=\frac{p+\delta}{\sum (p+\delta)} P=∑(p+δ)p+δ
- Laplace: P ( w ) = p ( W ) + m p ( ∑ P ( W ) ) + m P(w)=\frac{p(W)+mp}{(\sum P(W))+m} P(w)=(∑P(W))+mp(W)+mp
- 线性插值平滑: P ( w i ∣ w i − 2 w i − 1 ) = λ 1 P ( w i ∣ w i − 2 w i − 1 ) + λ 2 P ( w i ∣ w i − 1 ) + λ 3 P ( w i ) P(w_i|w_{i-2}w_{i-1})=\lambda_1P(w_i|w_{i-2}w_{i-1})+\lambda_2P(w_i|w_{i-1})+\lambda_3P(w_i) P(wi∣wi−2wi−1)=λ1P(wi∣wi−2wi−1)+λ2P(wi∣wi−1)+λ3P(wi)
对数线性模型
P ( Y = y ∣ X = x ) = exp w ⋅ ϕ ( x , y ) ∑ y exp w ⋅ ϕ ( x , y ) P(Y=y|X=x)=\frac{\exp w\cdot\phi(x,y)}{\sum_y\exp w\cdot\phi(x,y)} P(Y=y∣X=x)=∑yexpw⋅ϕ(x,y)expw⋅ϕ(x,y)
其中,w为权重
神经网络语言模型
- RNN
- Bidirectional Language Model
- Masked LM
- Permutation LM
文本分类
Naïve Bayes
a r g m a x c P ( c ∣ D o c ) = a r g m a x c P ( D ∣ c ) P ( c ) P ( D ) = a r g m a x c P ( D ∣ c ) P ( c ) argmax_c P(c|Doc)=argmax_c \frac{P(D|c)P(c)}{P(D)}=argmax_c P(D|c)P(c) argmaxcP(c∣Doc)=argmaxcP(D)P(D∣c)P(c)=argmaxcP(D∣c)P(c)
对于所有未出现的单词,使用加一平滑。
Bernoulli 文本模型
- 通过BOW生成每个文档的feature vector D i D_i Di, D i t D_{it} Dit表示其中第t个单词是否出现,即 D i ∈ { 0 , 1 } l D_i\in\{0,1\}^l Di∈{0,1}l
P ( D i ∣ c ) = ∏ t ∈ V P ( D i t ∣ c ) = ∏ ( D i t p + ( 1 − D i t ) ( 1 − p ) ) P(D_i|c)=\prod_{t\in V}P(D_{it}|c)=\prod (D_{it}p+(1-D_{it})(1-p)) P(Di∣c)=t∈V∏P(Dit∣c)=∏(Ditp+(1−Dit)(1−p))
Multinomial 文本模型
- BOW中每一位为代表词频的整数
a r g m a x c P ( D i ∣ c ) = n i ! ∏ t ∈ V D i t ! ∏ t ∈ V P ( w t ∣ c t ) D i t ⇔ a r g m a x c P ( c ) ∏ t P ( w t ∣ c t ) D i t argmax_c P(D_i|c)=\frac{n_i!}{\prod_{t\in V}D_{it}!}\prod_{t\in V}P(w_t|c_t)^{D_{it}} \\ \Leftrightarrow argmax_c P(c)\prod_t P(w_t|c_t)^{D_{it}} argmaxcP(Di∣c)=∏t∈VDit!ni!t∈V∏P(wt∣ct)Dit⇔argmaxcP(c)t∏P(wt∣ct)Dit
其中, n i n_i ni表示 D i D_i Di中单词数量
Feature utility measures
- 停词
- Frequency – select the most frequent terms
- Mutual information – select the terms with the highest mutual information (mutual information is also called information gain in this context
- I ( X , Y ) = ∑ y ∑ x p ( x , y ) l o g ( p ( x , y ) p ( x ) p ( y ) ) I(X,Y)=\sum_y\sum_xp(x,y)log(\frac{p(x,y)}{p(x)p(y)}) I(X,Y)=∑y∑xp(x,y)log(p(x)p(y)p(x,y))
- Χ2 (Chi-square)
- test independence of two events
- χ 2 ( D , t , c ) = ∑ e t ∈ { 0 , 1 } ∑ e c ∈ { 0 , 1 } ( N e t e c − E e t e c ) 2 E e t e c \chi^2(D,t,c)=\sum_{e_t\in\{0,1\}}\sum_{e_c\in\{0,1\}}\frac{(N_{e_te_c}-E_{e_te_c})^2}{E_{e_te_c}} χ2(D,t,c)=∑et∈{0,1}∑ec∈{0,1}Eetec(Netec−Eetec)2
Text representation
- Feature Vector
- Features Engineering
- Weight
- 0-1 vectors
- Count vectors
- tf-idf
- 用于评价词汇i对文档j的重要性
- tf: frequency of term, t f i , j = n i , j / ∣ D j ∣ tf_{i,j}=n_{i,j}/|D_j| tfi,j=ni,j/∣Dj∣,即词汇i在文档j中出现的频率。
- idf: inverse document frequency, i d f i = l o g ( N # i ∈ N ) idf_i = log(\frac{N}{\#\ i\in N}) idfi=log(# i∈NN),即文档数比出现词汇i的文档数的log。常在分母加一防止为零。
情感分类
- extract phrases containing adjectives or adverbs,
- estimate the semantic orientation of each phrase,
- classify the review based on the average semantic orientation of the phrases.
表示学习
Eymbolic Encoding
- One-Hot encoding:对词语的相似性没有假设。
- Bag-of-Words:0和1表示单词是否出现。简单,内存开销小。没有考虑词语出现顺序,稀疏,没有考虑语音关联(相似度)。
- N-Gram BOW:对每一个词典中的n-gram表示为vector的一位。
Latent Semantic Index 潜在语义索引
矩阵 X ∈ R m × n X\in R^{m\times n} X∈Rm×n, X ( i , j ) X(i,j) X(i,j)表示文本 i 在文档 j 中的出现次数,则使用SVD分解,可以将X表示成: X = U Σ V X=U\Sigma V X=UΣV。通过对 Σ \Sigma Σ 排序,舍弃较小的特征值(取前K个)实现降维度。通过列之间的乘积(cosine)代表相似度。
缺点
- 线性模型,对非线性依赖不是最优解
- 如何选取K
- 没有考虑出现顺序
- 添加新单词或文本需要重新计算。
Word2Vec
CBOW:通过上下文(window_size * 2)预测当前单词,每个词汇采用One-Hot编码。
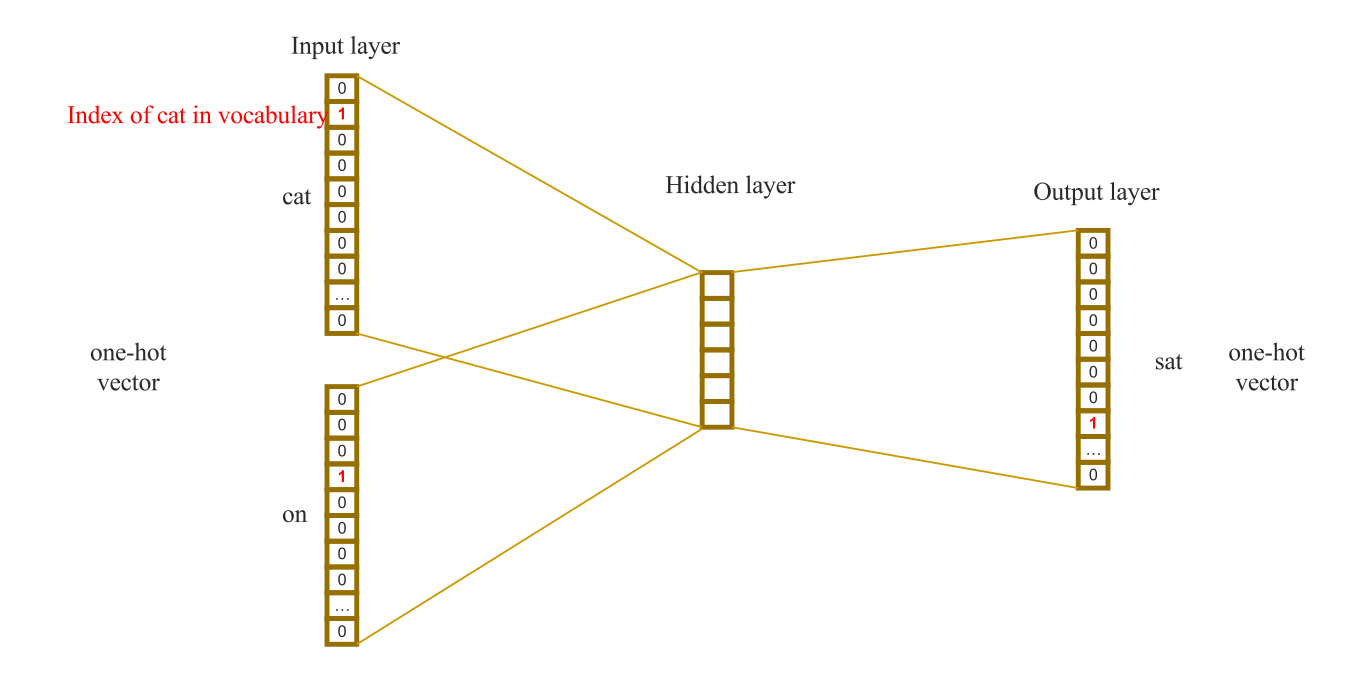
Skip-Gram:通过当前词预测上下文。
使用RNN完成文本任务。
词性标注和隐马尔科夫模型*
词性又称词类,是指词汇基本的语法属性。
- 划分依据:根据词的形态、词的语法功能、词的语法意义划分。
- 汉语:借用英文的词类体系;缺乏词性的变化
- 词性标注:
- 给某种语言的词标注上其所属的词类
- 对兼类词消歧
- 例:

- 词性标注歧义(兼类词):一个词具有两个或者两个以上的词性,如“上锁”和“门锁”。
- 当前方法正确率可以达到97%
- Baseline:给每个词标上它最常见的词性,所有的未登录词标上名词词性
马尔可夫模型
P ( S , w ) = ∏ i P ( S i ∣ S i − 1 ) P ( w i ∣ S i ) P(S,w)=\prod_i P(S_i|S_{i-1})P(w_i|S_i) P(S,w)=i∏P(Si∣Si−1)P(wi∣Si)
其中,S表示状态,w表示词汇。
基于两点假设:
- 有限视野:n-1阶马尔可夫模型的视野和n-gram一致。
- 时间独立性
转移矩阵 A n × n A_{n\times n} An×n,其中 a i j = P ( S j ∣ S i ) a_{ij}=P(S_j|S_i) aij=P(Sj∣Si)
隐马尔可夫模型
- 隐状态满足一阶马尔科夫模型,即当前状态仅与上一个状态有关。
- 输出具有独立性
- 何谓“隐”?
- 状态(序列)是不可见的(隐藏的)
- 什么样的问题需要HMM模型?
- 我们的问题是基于序列的,比如时间序列,或者状态序列。
- 我们的问题中有两类数据,一类序列数据是可以观测到的,即观测序列;而另一类数据是不能观察到的,即隐藏状态序列,简称状态序列。
对于隐马尔可夫模型 H M M : λ = ( S , V , A , B , Π ) HMM:\lambda=(S,V,A,B,\Pi) HMM:λ=(S,V,A,B,Π)
S为状态集,V为观察集
隐状态序列 Q = q 1 q 2 . . . q T Q=q_1q_2...q_T Q=q1q2...qT,观察序列 O = o 1 o 2 . . . o T O=o_1o_2...o_T O=o1o2...oT
隐状态转移分布 A = [ a i j ] , a i j = P ( q t = s j ∣ q t − 1 = s i ) A=[a_{ij}],a_{ij}=P(q_t=s_j|q_{t-1}=s_i) A=[aij],aij=P(qt=sj∣qt−1=si),即从隐状态 i 转移到隐状态 j 的概率。
观察值生成概率 B [ b j ( v k ) ] = P ( o k = v k ∣ q t = s t ) B[b_j(v_k)]=P(o_k=v_k|q_t=s_t) B[bj(vk)]=P(ok=vk∣qt=st),即当前隐状态j下生成观察值 o k o_k ok的概率
Π = [ Π i ] , Π i = P ( q 1 = s j ) \Pi=[\Pi_i],\Pi_i=P(q_1=s_j) Π=[Πi],Πi=P(q1=sj)为初始状态概率分布
例:

Viterbi算法
求解观测序列,最可能的状态状态序列(模型解码)。Viterbi算法为动态规划方法。
定义
δ
t
(
i
)
\delta_t(i)
δt(i)为t时刻时,隐状态为
s
i
s_i
si,输出为序列
w
1
.
.
.
w
t
w_1...w_t
w1...wt概率最大的隐藏状态路径:
δ
t
(
i
)
=
max
s
1
s
2
.
.
.
s
t
−
1
P
(
P
o
s
1
.
.
.
P
o
s
t
−
1
,
P
o
s
t
=
s
i
,
w
1
.
.
.
w
t
)
\delta_t(i)=\max_{s_1s_2...s_{t-1}} P(Pos_1...Pos_{t-1},Pos_t=s_i,w_1...w_t)
δt(i)=s1s2...st−1maxP(Pos1...Post−1,Post=si,w1...wt)
算法如下:
初始化: δ 1 ( i ) = max P ( P o s 1 = s i , w 1 ) = π i b i ( w 1 ) \delta_1(i)=\max P(Pos_1=s_i,w_1)=\pi_ib_i(w_1) δ1(i)=maxP(Pos1=si,w1)=πibi(w1)
迭代:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ \delta_{t+1}(j…
令 ∣ S ∣ = N |S|=N ∣S∣=N,则每计算一个 δ t ( i ) \delta_t(i) δt(i),要计算从t-1时刻所有状态到 s i s_i si的概率,时间复杂度为 O ( N ) O(N) O(N),每个时刻t需要计算N个状态 δ ( s 1 . . . s N ) \delta(s_1...s_N) δ(s1...sN),时间复杂度为 O ( N 2 ) O(N^2) O(N2),且序列长为T,因此算法时间复杂度为 O ( N 2 T ) O(N^2T) O(N2T)
MEMM 最大熵马尔可夫模型
句法分析*
上下文无关文法
对于文法 G = ( N , T , S , R ) G=(N,T,S,R) G=(N,T,S,R)
- N是非终结符号集合
- T是终结符号集合
- S是开始符号
- R是产生式规则
和编译原理一样,按照语法规则产生语法树。
自顶向下句法分析
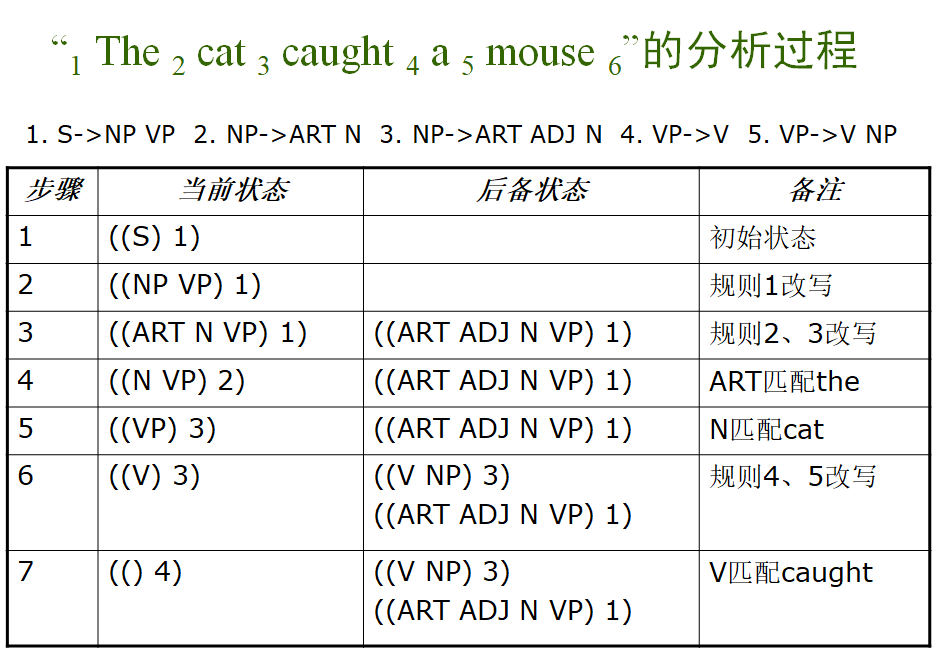
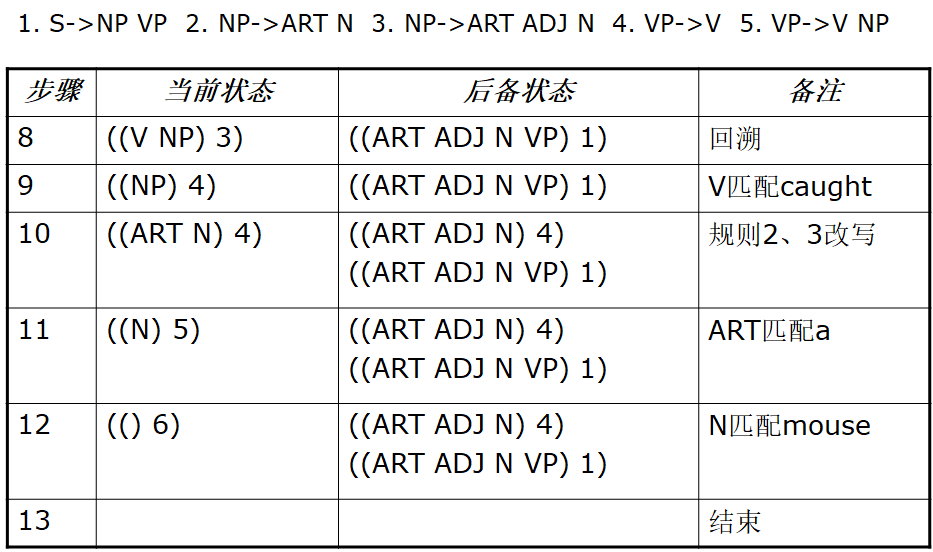
算法:
取 ((S) 1)作为当前状态(初始状态),后备状态为空。
若当前状态为空,则失败,算法结束,
否则,若当前状态的符号表为空,
- 位置计数器值处于句子末尾,则成功,算法结束
- 位置计数器值处于句子中间,转5
否则,进行状态转换,若转换成功,则转2
否则,回溯,转2。
例子:
歧义
程序设计语言可以通过约束避免歧义,如LL(1)语法,LR语法。而自然语言无法避免歧义。
概率上下文无关文法
每一个产生式都有其概率,语法树的概率即所有边的概率乘积。
分析算法
a r g m a x G P ( W ∣ G ) argmax_G P(W|G) argmaxGP(W∣G),分配所有语法规则的概率
向内算法
对于规则
A
→
B
C
A\rightarrow BC
A→BC
α
i
,
j
(
A
)
=
P
(
w
i
.
.
.
w
j
∣
A
)
=
∑
B
,
C
,
k
P
(
A
→
B
C
)
α
i
,
k
(
B
)
α
k
+
1
,
j
(
C
)
α
i
,
i
=
P
(
A
→
w
i
)
\alpha_{i,j}(A)=P(w_i...w_j|A)=\sum_{B,C,k}P(A\rightarrow BC)\alpha_{i,k}(B)\alpha_{k+1,j}(C) \\ \alpha_{i,i}=P(A\rightarrow w_i)
αi,j(A)=P(wi...wj∣A)=B,C,k∑P(A→BC)αi,k(B)αk+1,j(C)αi,i=P(A→wi)
词串概率:
P
(
S
→
w
1
.
.
.
w
n
∣
G
)
=
α
1
,
n
(
S
)
P(S\rightarrow w_1...w_n|G)=\alpha_{1,n}(S)
P(S→w1...wn∣G)=α1,n(S)
向外算法
定义
β
i
,
j
(
A
)
\beta_{i,j}(A)
βi,j(A)为通过语法G,通过A推出
w
i
.
.
.
w
j
w_i...w_j
wi...wj的概率,且有语法规则
C
→
A
B
,
C
→
B
A
C\rightarrow AB,C\rightarrow BA
C→AB,C→BA则有
β
1
,
n
(
A
)
=
(
A
=
S
)
?
1
e
l
s
e
0
β
i
,
j
(
A
)
=
∑
B
,
C
,
j
<
k
β
i
,
k
(
C
)
P
(
C
→
A
B
)
α
j
+
1
,
k
(
B
)
+
∑
B
,
C
,
h
<
i
β
h
,
j
(
C
)
P
(
C
→
B
A
)
α
h
,
i
−
1
(
B
)
\beta_{1,n}(A)=(A=S)?1\ else\ 0 \\ \beta_{i,j}(A)=\sum_{B,C,j<k}\beta_{i,k}(C)P(C\rightarrow AB)\alpha_{j+1,k}(B)+\sum_{B,C,h<i}\beta_{h,j}(C)P(C\rightarrow BA)\alpha_{h,i-1}(B)
β1,n(A)=(A=S)?1 else 0βi,j(A)=B,C,j<k∑βi,k(C)P(C→AB)αj+1,k(B)+B,C,h<i∑βh,j(C)P(C→BA)αh,i−1(B)
词串概率:
P
(
w
1
n
∣
G
)
=
∑
A
,
k
β
(
A
)
P
(
A
→
w
k
)
P(w_{1n}|G)=\sum_{A,k}\beta(A)P(A\rightarrow w_k)
P(w1n∣G)=A,k∑β(A)P(A→wk)
信息抽取
Relation Classification
通过文本预测两个实体之间的关系。如果使用监督学习,则需要大量的标记数据。
Distant Supervision
自动生成大量标记数据。
-
方法:如果两个实体在KB(知识库)中具有关系R,则所有包含两个实体的句子都被标记为关系R。
-
缺点:不可避免的会有噪声(标签错误)。
Noise 噪声
- 假阳性:两个实体没有被标记的关系
- 假阴性:本来具有关系(且在数据集中表现出来)的实体对被标记为没有关系(NA)
Suppress Noise 压缩噪声
降低假阳性的重要性,为每一条句子分配权重。
- 假设:
- 至少一个句子会提及两个实体的关系。
- Multi-Instance Learning:所有提及相同对实体的句子会被装进一个bag中,在bag之间进行训练。
- 为bag中的句子分配权重,权重和为1
- 缺点:
- 无法处理bag中没有描输两个实体关系的情况。(不满足假设的情况)
- 假阴性没有处理
Removing Noise 移除噪声
将假阳性句子移除数据集。
- 方法:通过reinforcement learning学习一个判别器,通过classifer的反馈训练。
- 缺点:
- 假阴性没有处理
Rectify Noise 修正噪声
将错误标签更正为正确标签,假阳性修正为正确标签或NA,假阴性从NA修正为阳性。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)