机器学习概念总结
文章目录机器学习监督学习功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出导入机器学习机器学习主要有两个权威的定义:由...
文章目录
定义
机器学习主要有两个权威的定义:
- 由Arthur samuel给出的定义:在不直接针对特定问题进行编程的情况下,赋予计算机学习能力的一个研究领域。
- 由Tom Mitchell给出的定义: 对于某类任务T和性能度量P,如果计算机程序在T上以P衡量的性能随着经验E而自我完善,那么就称这个计算机程序从经验E学习。
监督学习
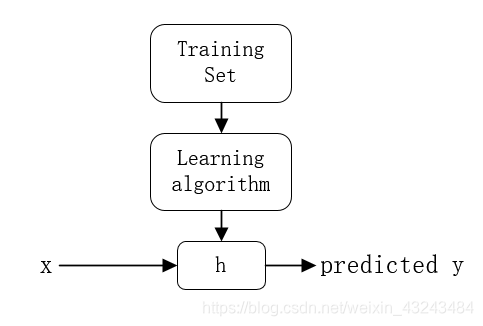
监督学习(Supervised Learning)是指对于给定的训练集,已知每一个样本的正确输出,通过训练找出输入与输出之间的关系,从而预测未标记样本的输出值。监督学习主要分为回归和分类两种。
线性回归
线性回归(Linear Regression)在假设特征满足线性关系,根据给定的训练数据训练一个模型,并用此模型进行预测。
假设:
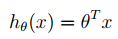
代价函数:
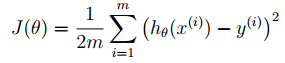
优化目标:
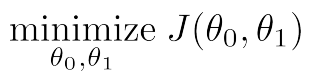
求解方法1:梯度下降
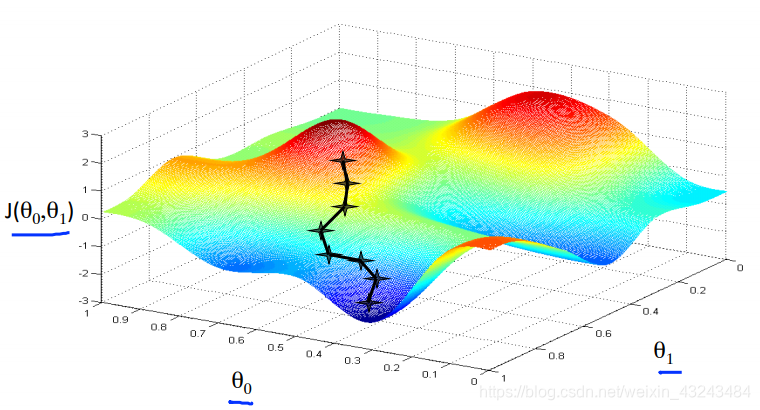
从一组参数θ开始,以减小代价函数J(θ)为目的改变θ;
优化方向:
![]()
α:学习速率
求解方法2:最小二乘
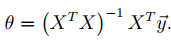
| 梯度下降 | 最小二乘法 |
|---|---|
| 需要选择学习速率α | 不需要选择学习速率 |
| 需要多次迭代 | 不需要迭代 |
| 当样本特征数n很大时依然适用O(kn2) | 样本特征数增大时计算量过大O(n3) |
特征缩放
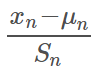
其中:μn为平均值,Sn为最大值-最小值。
正则化
代价函数:
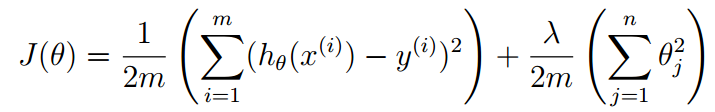
其中:λ为正则系数,过小容易过拟合,过大容易欠拟合。
偏导数:
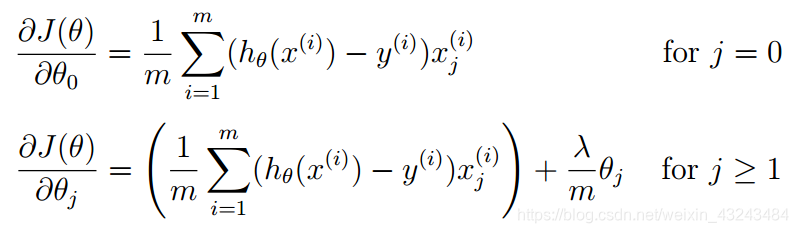
最小二乘法求解:

逻辑回归
逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
假设:
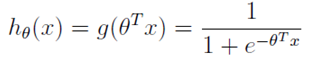
代价函数:
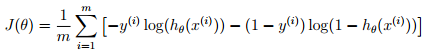
S型函数
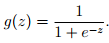
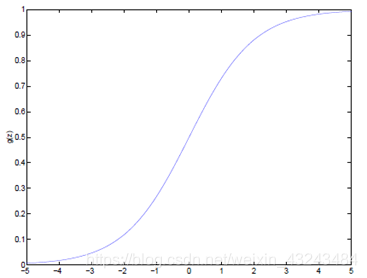
函数当z趋近于无穷大时,g(z)趋近于1;当z趋近于无穷小时,g(z)趋近于0。图形如下:
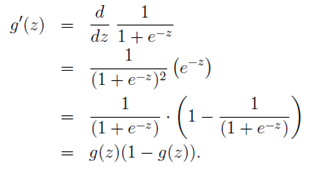
求解方法:
- Gradient descent
- Conjugate gradient
- BFGS
- L-BFGS
多分类: One-VS-All
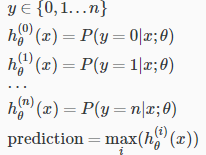
正则化
代价函数:
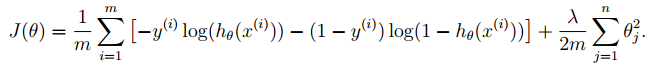
导数:
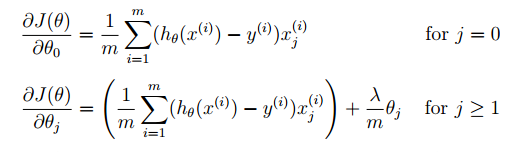
神经网络
- L:神经网络的层数
- sl:第l层的单元数
- K:输出单元的数目
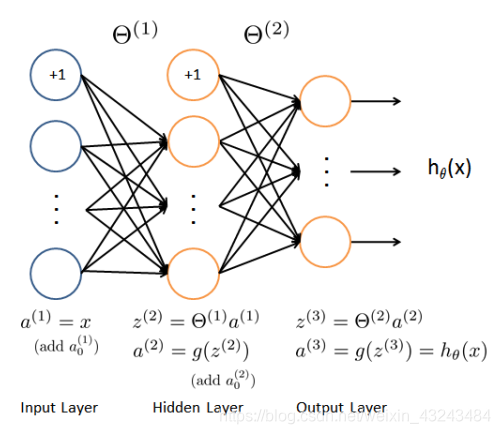
正则化代价函数
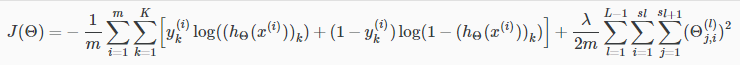
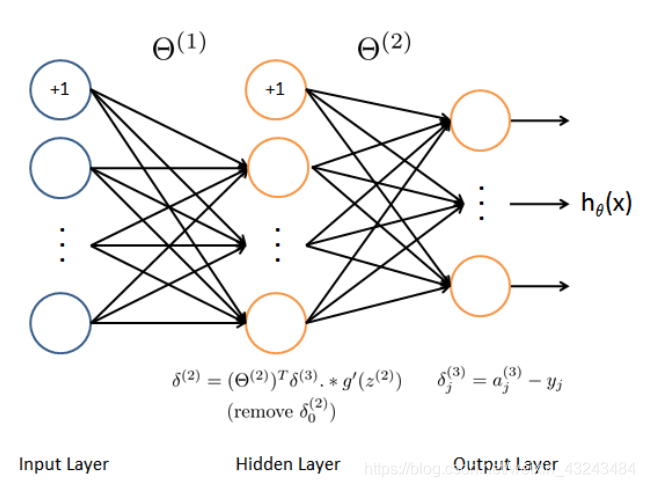
反向传播法
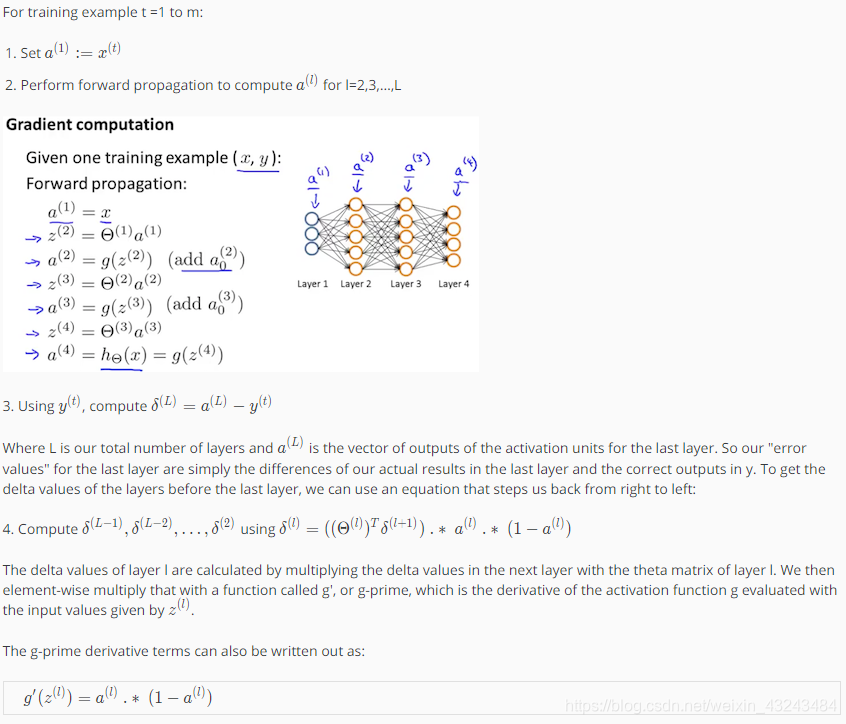

梯度检验
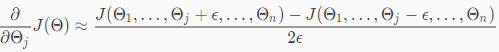
epsilon = 1e-4;
for i = 1:n,
thetaPlus = theta;
thetaPlus(i) += epsilon;
thetaMinus = theta;
thetaMinus(i) -= epsilon;
gradApprox(i) = (J(thetaPlus) - J(thetaMinus))/(2*epsilon)
end;
算法步骤
- 随机初始化参数θ;
- 运用前向传播方法得到每一个样本x的预测值h(x);
- 计算代价函数
- 使用后向传播算法计算偏导数
- 使用梯度检验保证后向传播算法的正确性,然后去除梯度检验;
- 使用梯度下降法或其他优化算法最小化代价函数求取参数θ。
模型评价
学习曲线
数据集划分:
- 训练集(Training set):60% 用于最优化参数θ;
- 交叉验证集(Cross validation set):20% 用于找到最小误差的多项式;
- 测试集(Test set):20% 用于估计泛化误差。
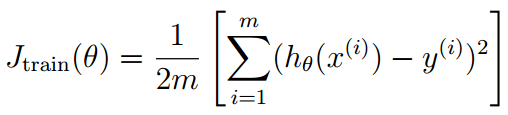
高偏差(High bias)(欠拟合):Jtrain和JCV都很高,且大约相等。
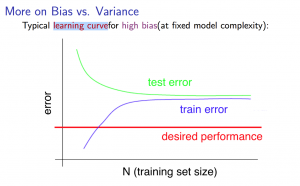
高方差(High variance)(过拟合):Jtrain较低,JCV比Jtrain大很多。
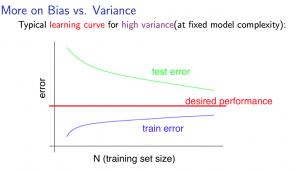
改进方向
固定高方差:
- 寻找更多训练样本
- 缩小样本特征
- 增大正则系数λ
固定高偏差:
- 增加样本特征
- 增加多项式特征
- 减小正则系数λ
支持向量机
支持向量机(Support Vector Machines,SVM)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化(Large Margin),最终转化为一个凸二次规划问题来求解。由简至繁的模型包括:
- 当训练样本线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机;
- 当训练样本近似线性可分时,通过软间隔最大化,学习一个线性支持向量机;
- 当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机;
求解模型
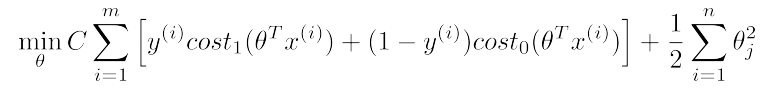
左图为cost1,右图为cost0
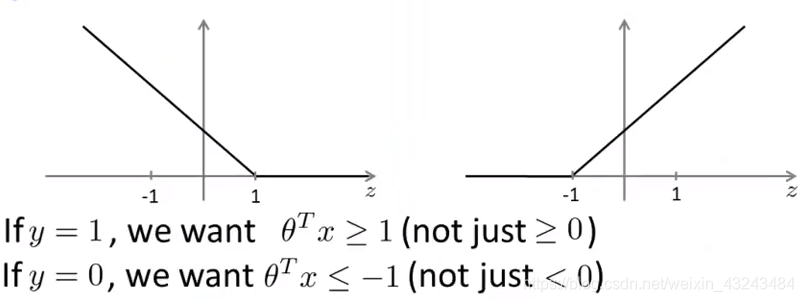
核函数
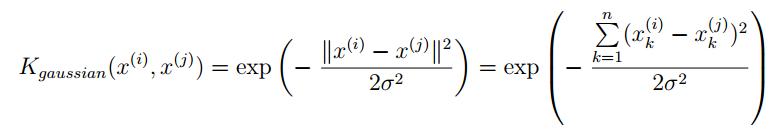
SVM with Kernels:
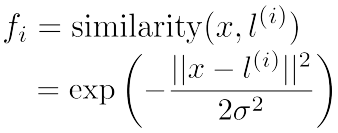
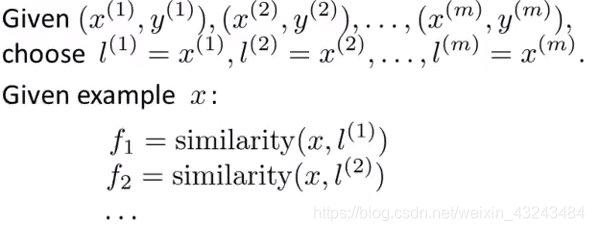
假设:
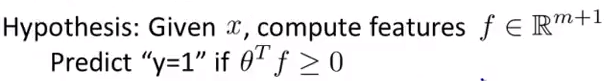
优化目标:
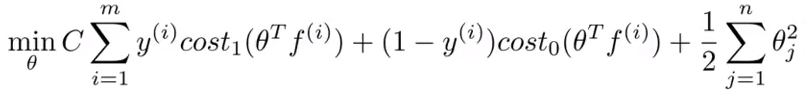
参数影响:
- 增大C:降低偏差,增大方差;
- 减小C:增大偏差,减小方差;
- 增大σ2: fi 更加平滑,增大偏差,降低方差;
- 减小σ2: fi 更加陡峭,降低偏差,增大方差。
核函数种类:
线性核函数(Linear kernel)、高斯核函数(Gaussian kernel)、多项式核函数(Polynomial kernel)、字符串核函数(String kernel)、卡方核函数(Chi-square kernel)、直方图交叉核函数(Histogram intersection kernel)…
Logistic Regression VS SVM
n为样本的特征数,m为训练集样本数量。
- n很大:逻辑回归或线性核函数(无核)SVM;
- n较小,m中等:高斯核函数SVM;
- n较小,m较大:增加特征数目,使用逻辑回归或无核SVM。
无监督学习
无监督学习(Unsupervised Learning)中,提前不知道结果是什么样子,但可以通过聚类的方式从数据中提取一个特殊的结构。在无监督学习中给定的数据是和监督学习中给定的数据是不一样的。在无监督学习中给定的数据没有任何标签或者只有同一种标签。
聚类—K-means算法
输入:
- K(聚类中心数目)
- 训练集{x(1) , x(2) , … , x(m)}
变量:
- c(i):样本x(i)所属的聚类中心编号;
- μk:聚类中心K;
- μc(i):样本x(i)所属的聚类中心。
优化目标:
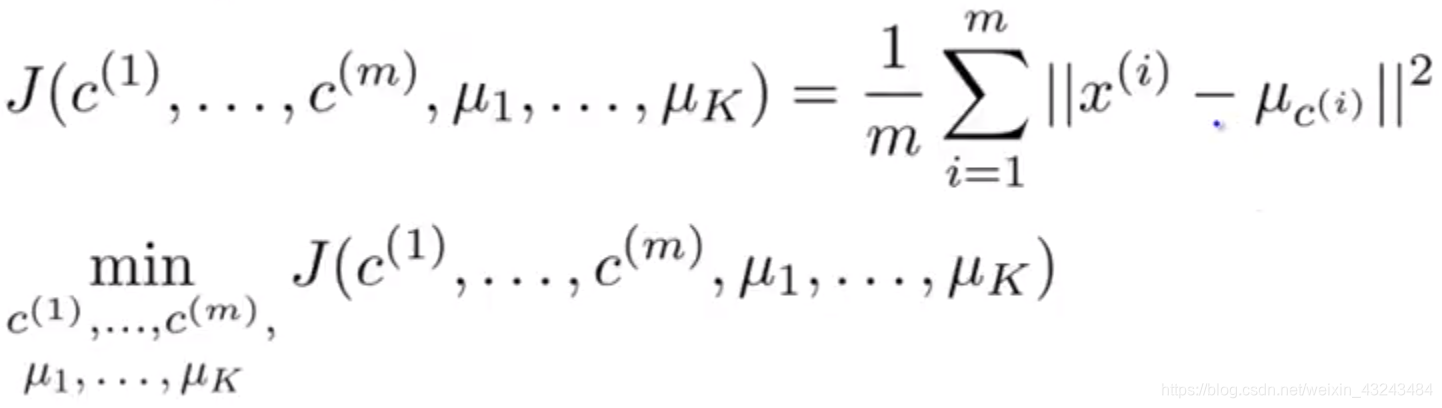
步骤:
- 随机初始化K个聚类中心
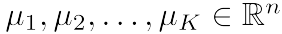
- 重复以下步骤:

为了保证收敛到全局最优解,通常需要执行数次K-meams算法,每次选择不同的随机初始化聚类中心,选择代价函数最小的一次算法运行结果。

维数约减
目的
- 数据压缩(Data Compression)不仅使得数据占用更少的内存和硬盘空间,还能给算法提速。
- 数据可视化(Data Visualization)通过将数据由高位约减到二维或者三维,能够以图形方式呈现数据。
主成分分析PCA
数据预处理
对于训练集{x(1) , x(2) , … , x(m)}作特征缩放/均值归一化处理:
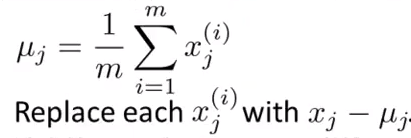
步骤:
- 计算协方差矩阵(Covariance matrix):
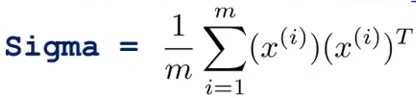
- 计算特征向量(Eigenvetors):
[U,S,V] = svd(Sigma);
其中:
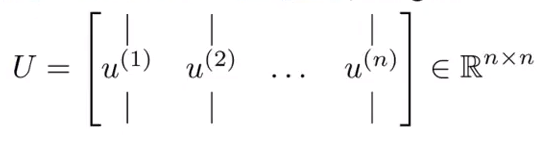
- 取矩阵U的前K列得到矩阵Ureduce。
Ureduce = U(:,1:k);
- 降维:
z = Ureduce' * x;
- 数据恢复:
xapprox = Ureduce * z;
K(主成分数目)的选择:
假设想要数据集99%的变化被保留。
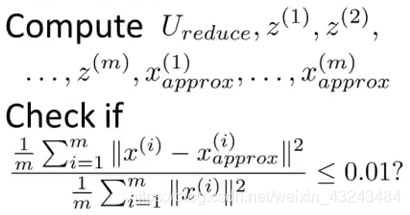
即在[U,S,V] = svd(Sigma)中,选择最小的k使得:
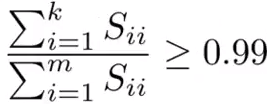
异常检测
举例-网站欺诈行为检测
- x(i):用户的行为特征;
- p(x):由数据集训练的模型;
- 如果p(x)<ε,则认为该用户行为异常。
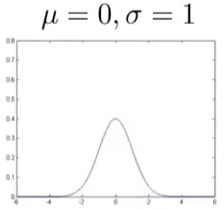
高斯分布
函数表达式:
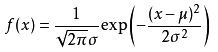
图形:
算法步骤
- 选取可能指示异常现象的特征xi;
- 计算参数μ1,μ2,…μn,σ12,σ22,…σn2
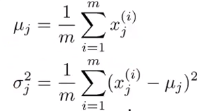
- 对于新的样本x,计算p(x):
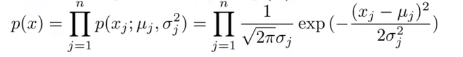
如果p(x)<ε,则认为该样本异常。
多元高斯分布
不再计算p(x1),p(x2),…,直接计算p(x)。
![]()
图形:
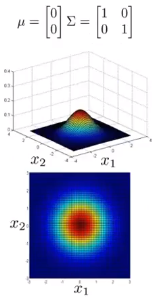
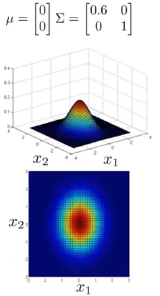
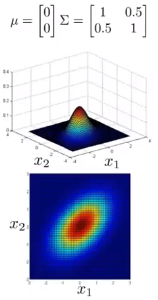
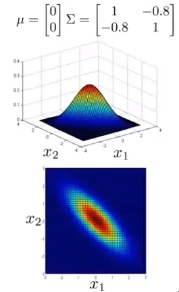
表达式:
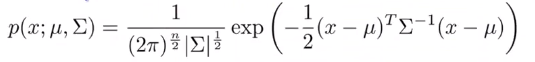
参数计算:
对于训练集{x(1),x(1),… ,x(m)}
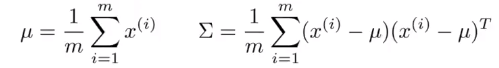
推荐系统
问题描述
电影打分:
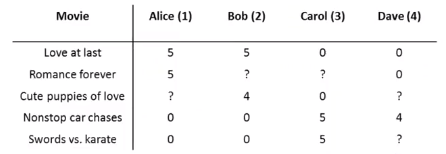
参数:
- nu:用户数量;
- nm:电影数量;
- r(i,j):如果用户j给电影i打过分,则r(i,j)=1;
- y(i,j):用户j给电影i的分数。
基于内容的推荐
参数:
- θ(j):用户j的参数向量(待求);
- x(i):电影i的特征向量(已知);
用户j对电影i的打分预测为:(θ(j))T(x(i))。
优化目标:
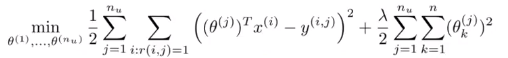
梯度下降:
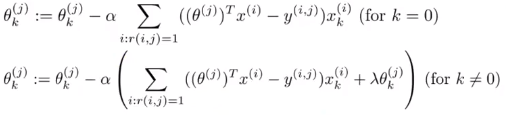
协同过滤
参数:
- θ(j):用户j的参数向量(未知);
- x(i):电影i的特征向量(未知);
代价函数:
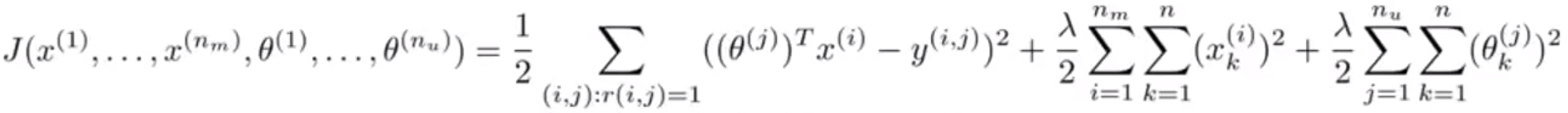
步骤:
- 随机初始化x(1),x(2),…,x(nm),θ(1),θ(2),…,θ(nu)。
- 使用梯度下降法最小化代价函数J(x(1),x(2),…,x(nm),θ(1),θ(2),…,θ(nu)):
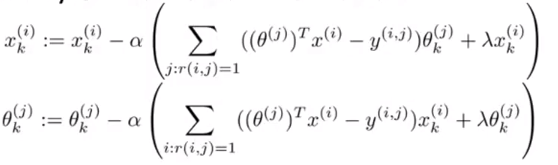
- 参数向量为θ的用户对特涨向量为x的电影的预测打分为:θTx。
均值归一化:
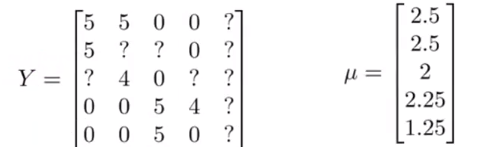
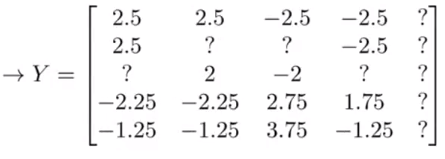
参数向量为θ的用户对特涨向量为x的电影的预测打分为:θTx + μi。
大数据下的机器学习
随机梯度下降
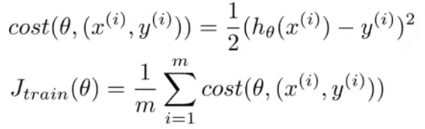
步骤:
- 随机打乱训练集;
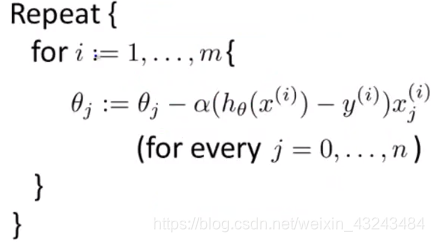
小批量梯度下降
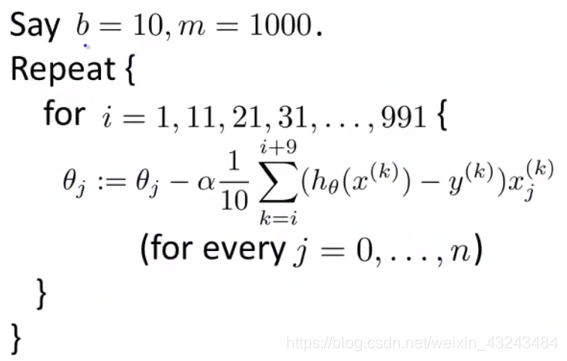
其他方法
- 在线学习(Online Learning)
- 映射约简(Map Reduce)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)