ICCV 2021 LargeFineFoodAI 检索赛道方案总结
ICCV 2021 Workshop LargeFineFoodAI Large-Scale Fine-Grained Food Analysis2021年6月份美团主办的大规模细粒度的比赛,比赛共有两个赛道,分别是分类和检索,比赛在kaggle上举办的,比赛主页:LargeFineFoodAI分类赛道检索赛道比赛每个赛道分别产生了前三名的方案介绍,在官网主页也有,但是是视频形式的,现在根据他们的
ICCV 2021 Workshop LargeFineFoodAI Large-Scale Fine-Grained Food Analysis——Retrieval

2021年6月份美团主办的大规模细粒度的比赛,比赛共有两个赛道,分别是分类和检索,比赛在kaggle上举办的,比赛主页:
比赛每个赛道分别产生了前三名的方案介绍,在官网主页也有,但是是视频形式的,现在根据他们的方案改成文字形式的。
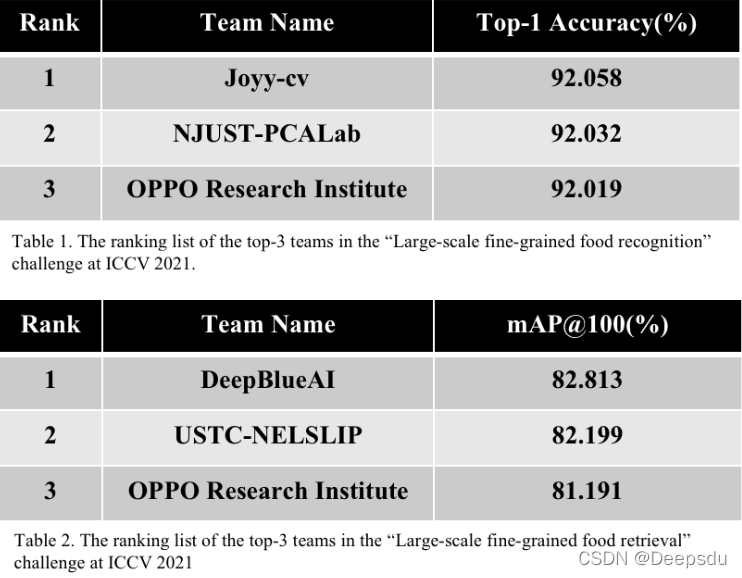
1 检索赛道
第一名 DeepBlueAI
这名方案介绍比较水,方案细节很不好。
使用的方案:
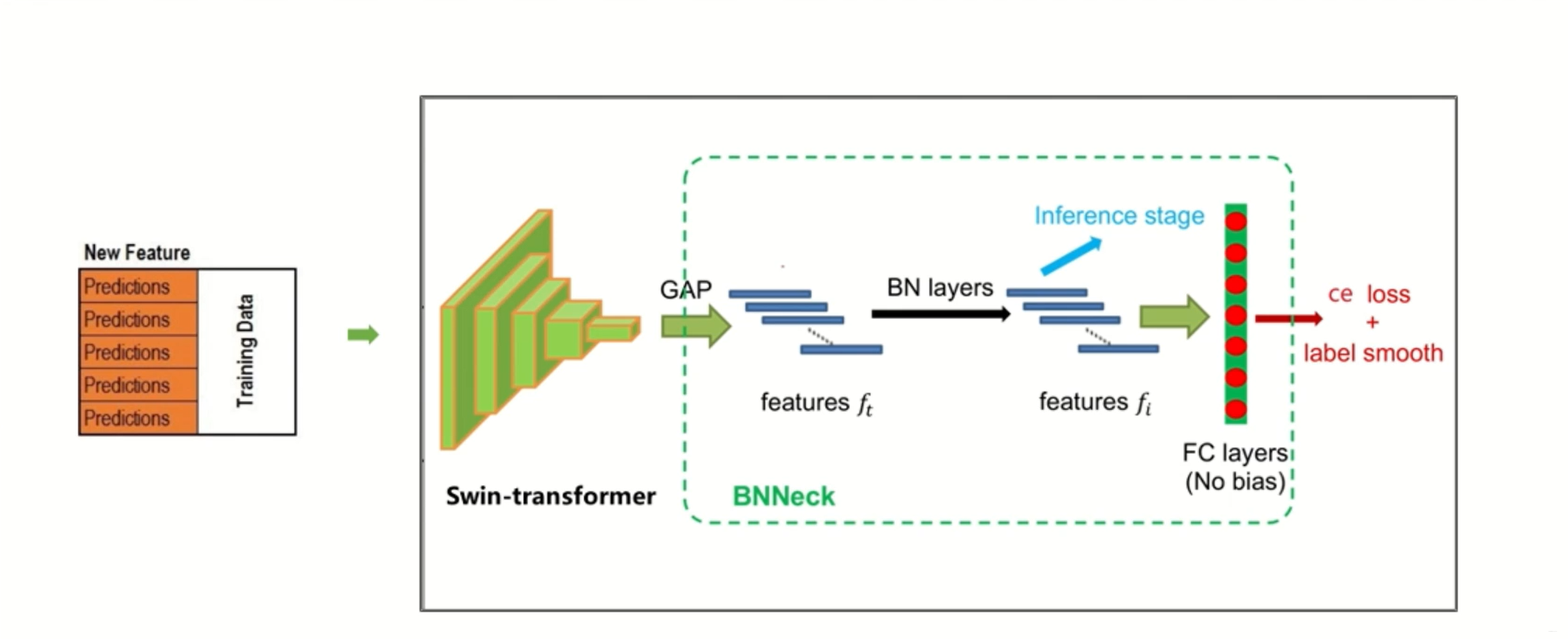
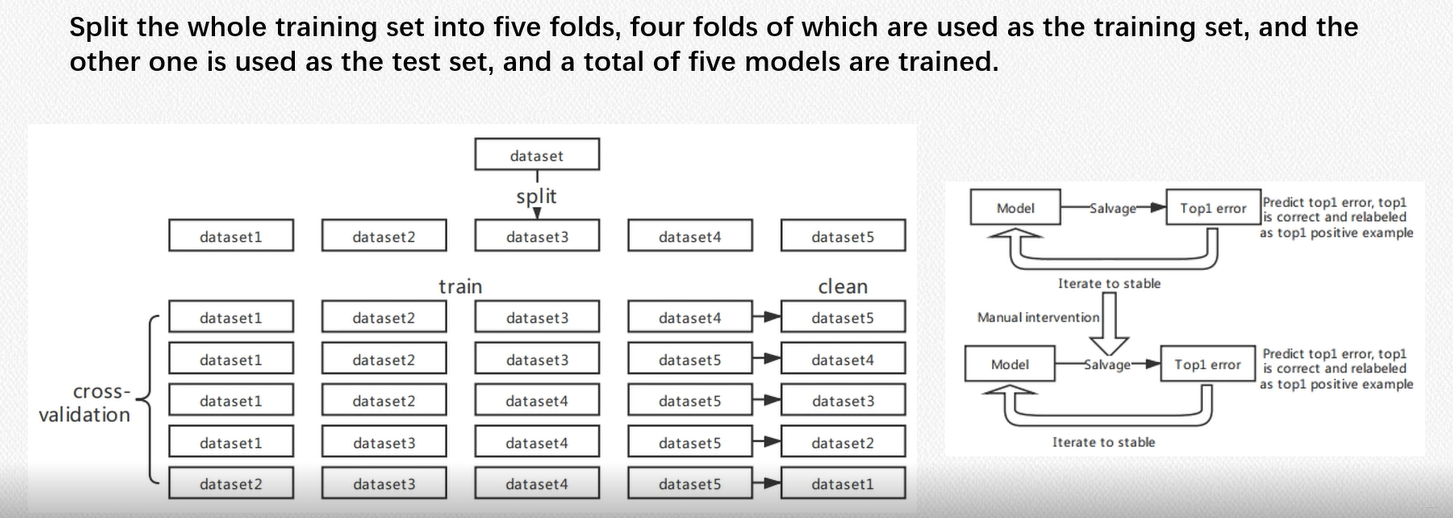
- 五折交叉验证
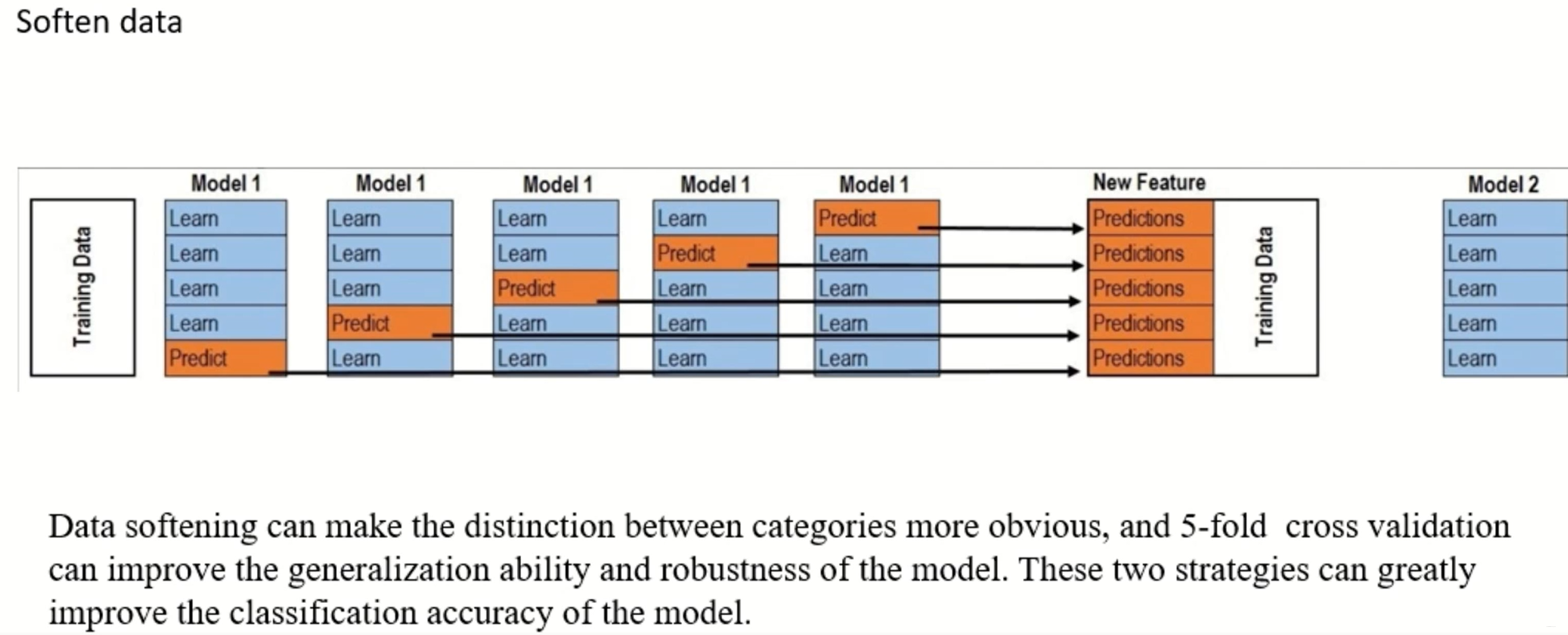
- Data softening,对数据进行清洗的操作,还挺新颖的
- Cutmix
- Labelsmothing
- SAM(Sharpness-Aware Minimization) 优化器
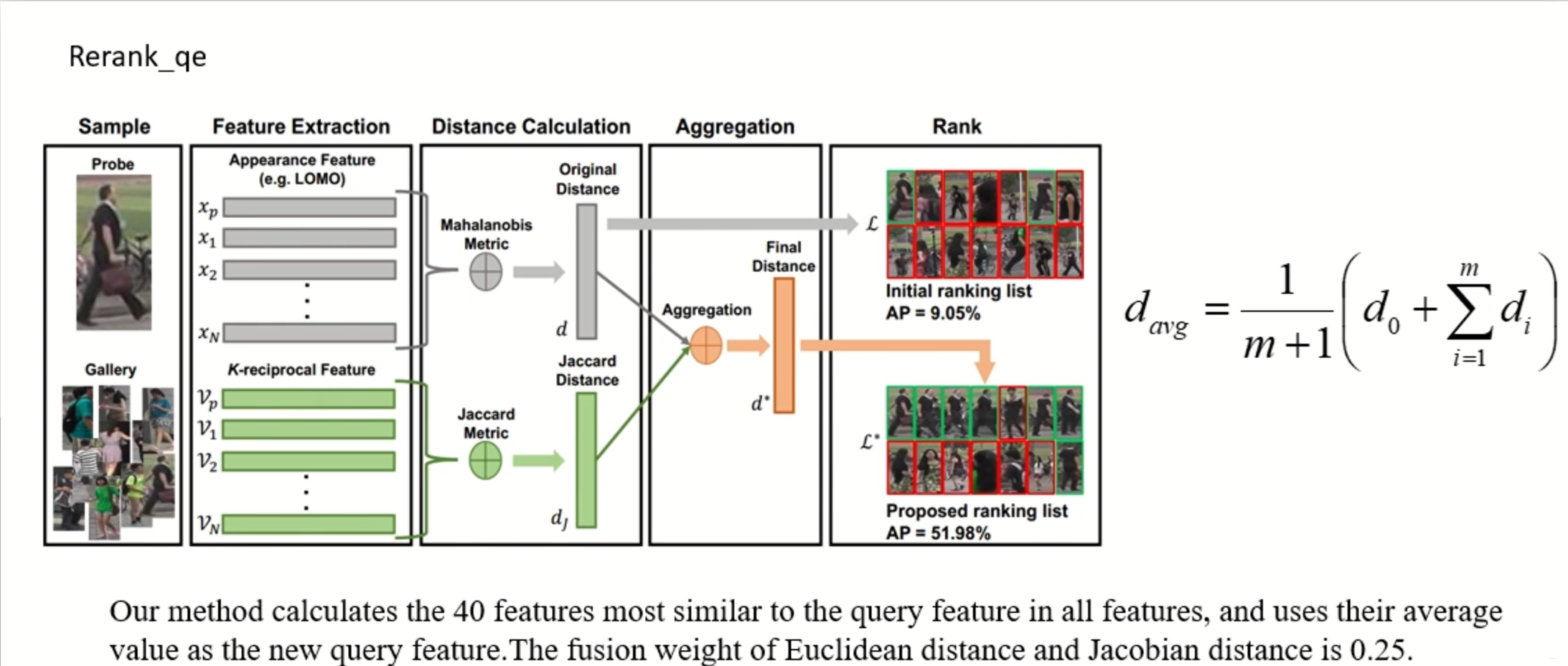
- Query Expansion 对索引的query的特征进行拓展,从而增强这个query,使用的距离是Euclidean和Jacobian distance。
- Model Ensemble
结果

一些没有用的方法:

第二名 USTC-NELSLIP
整体方案:
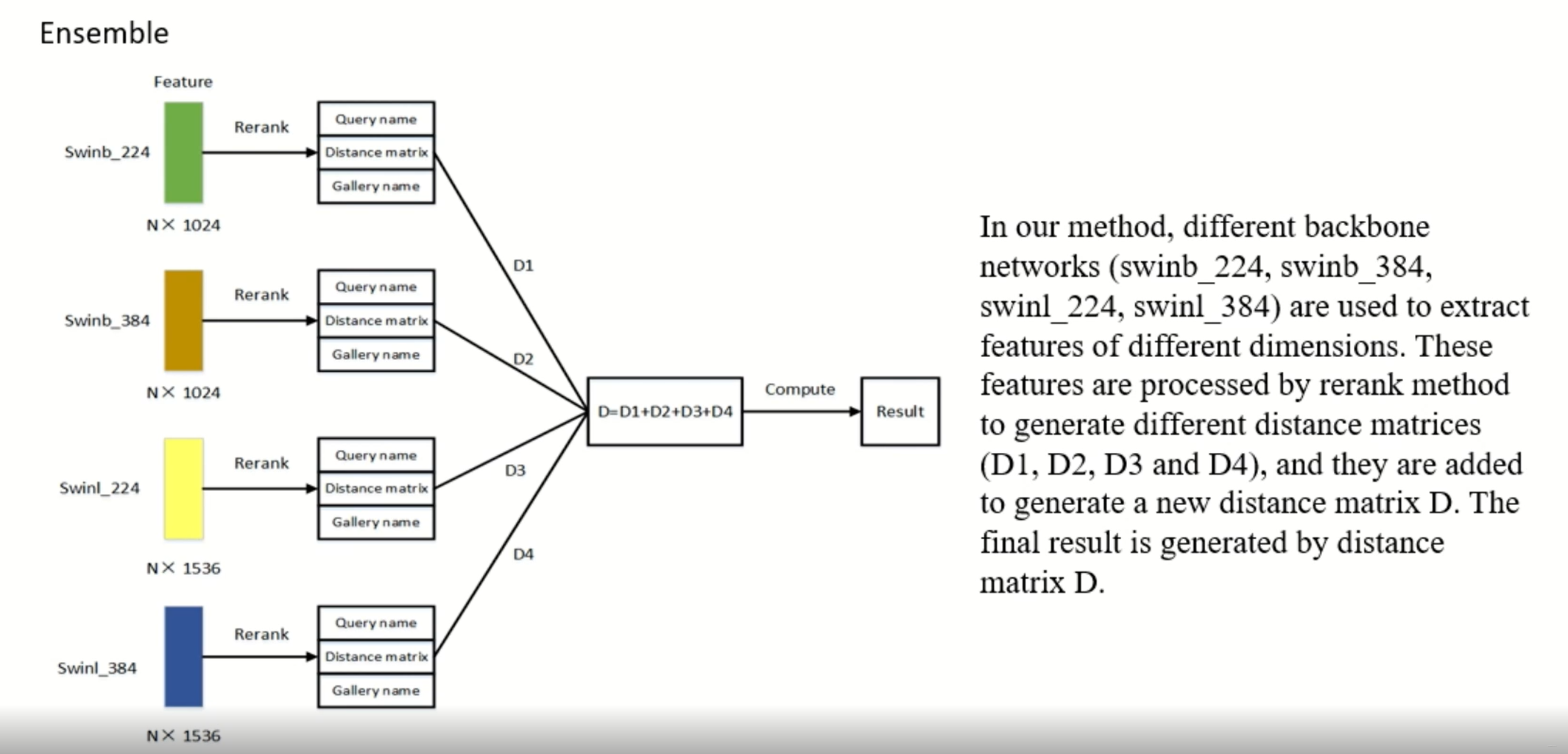
- 数据清洗 这部分和第一名的方案很相似
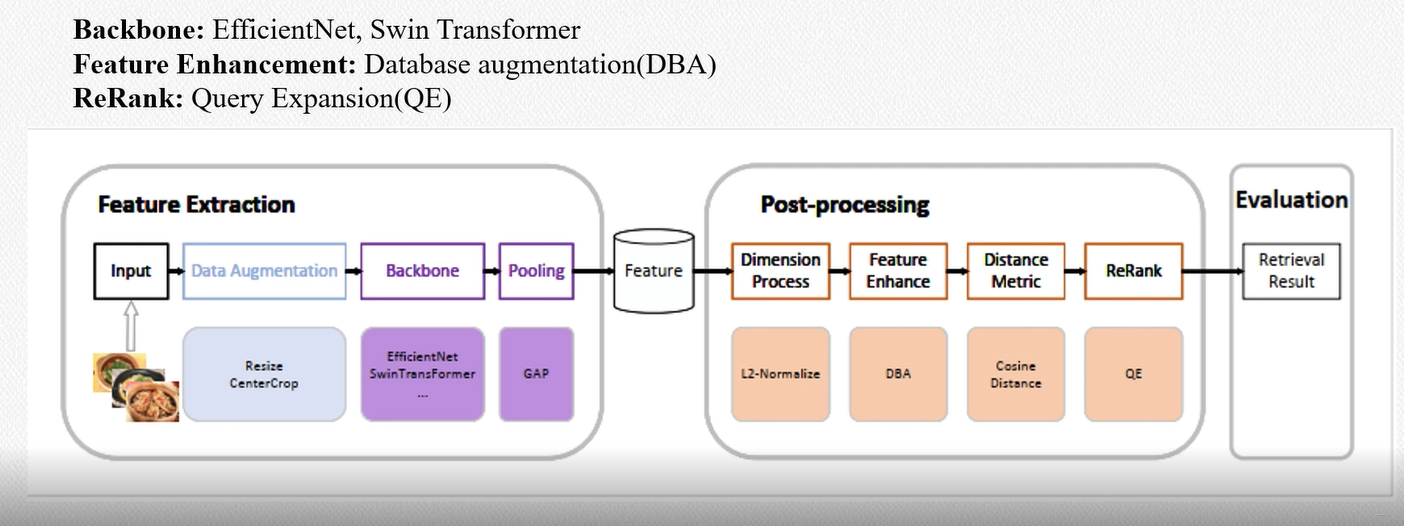
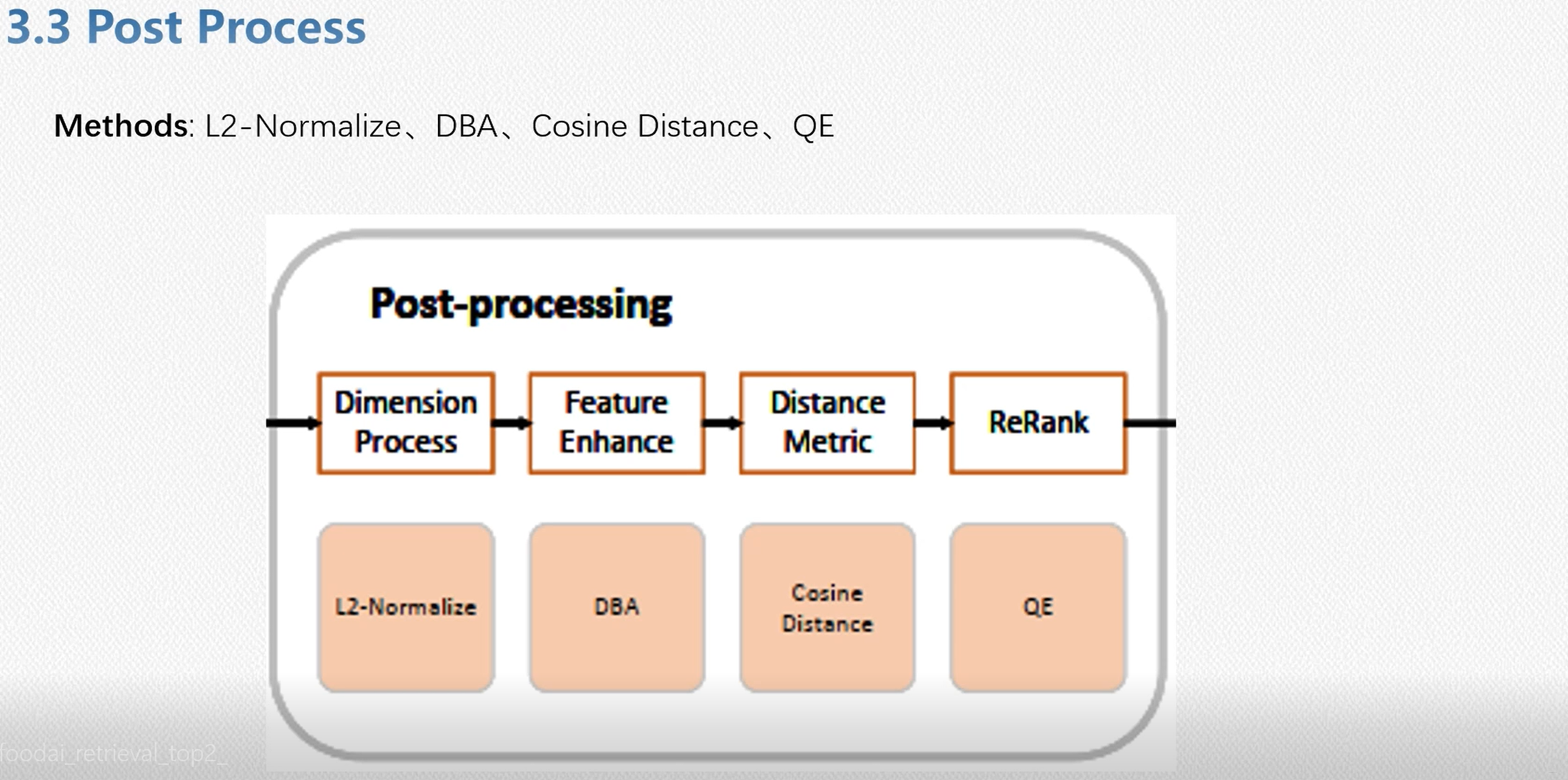
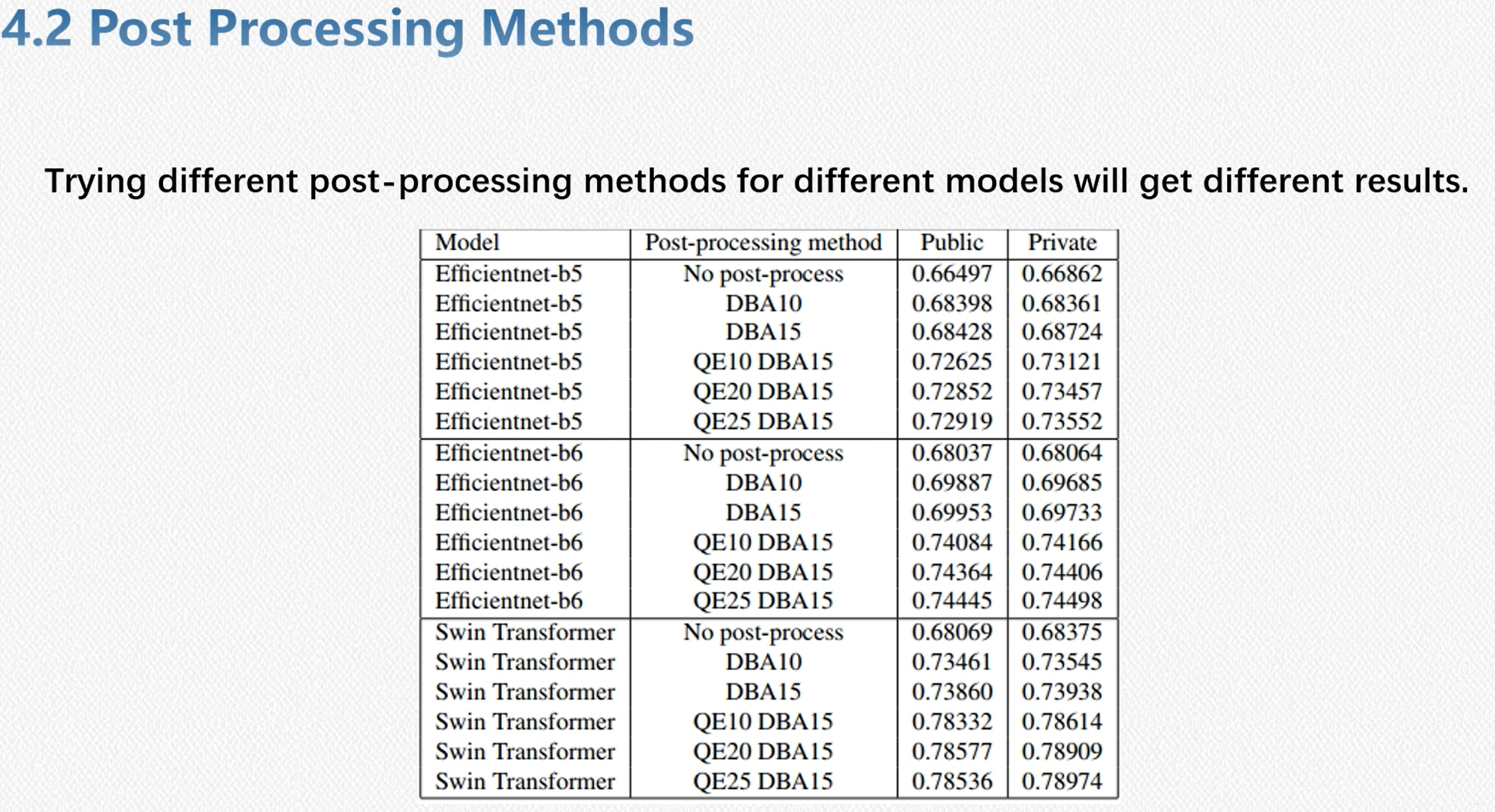
- 后处理阶段,其中QE和DBA是比较有用的方案
细节

最终结果
第三名 OPPO
整体方案:
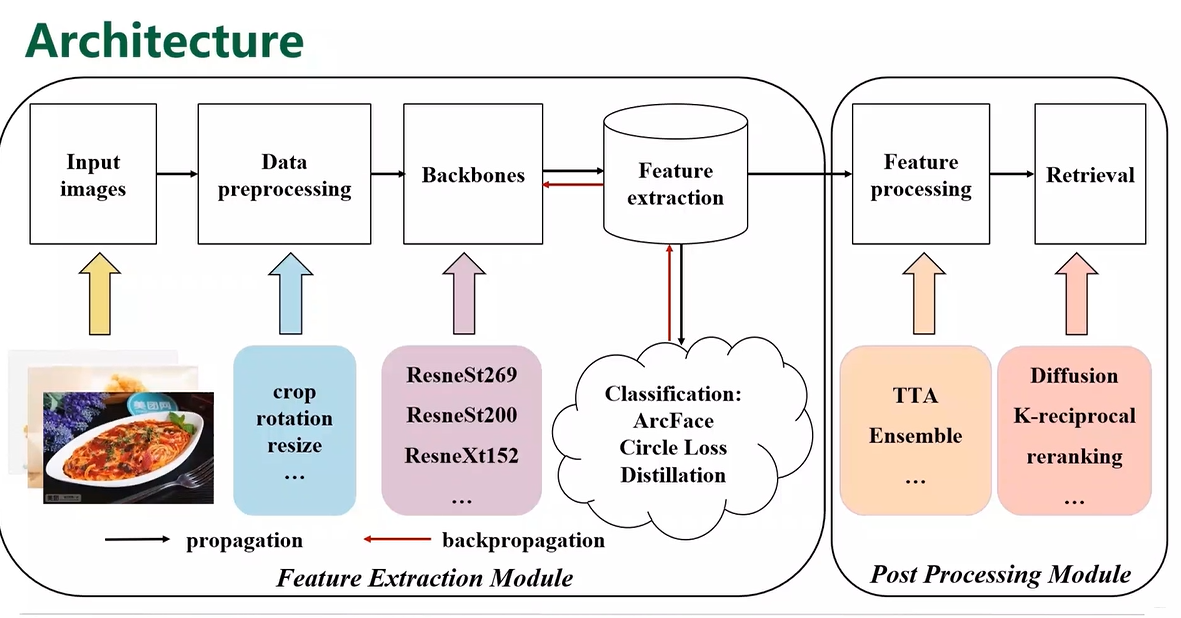
- Backbone和Data Processing

- 训练策略

- Loss
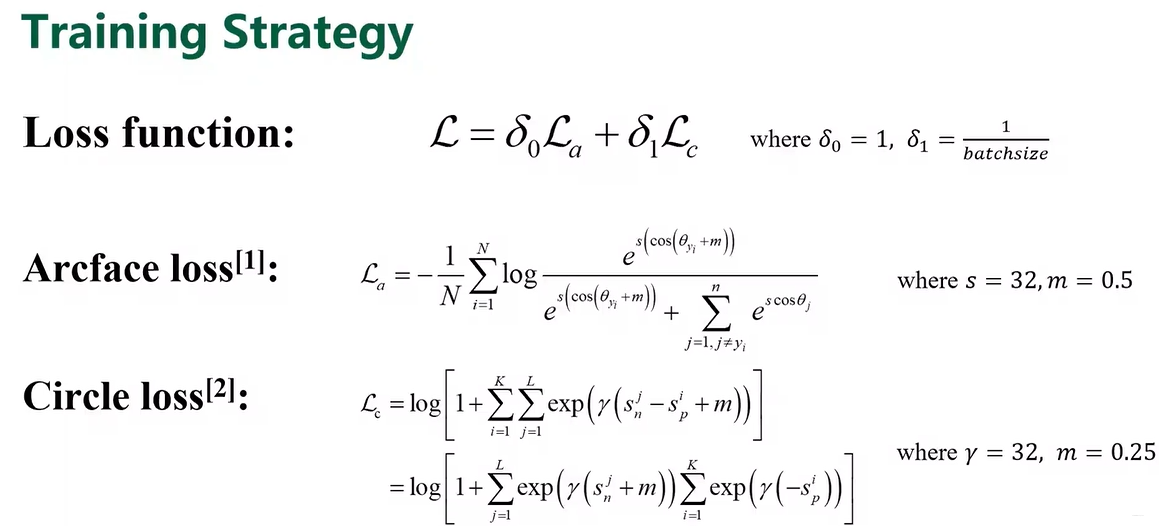
- 模型蒸馏,这部分有点没听懂

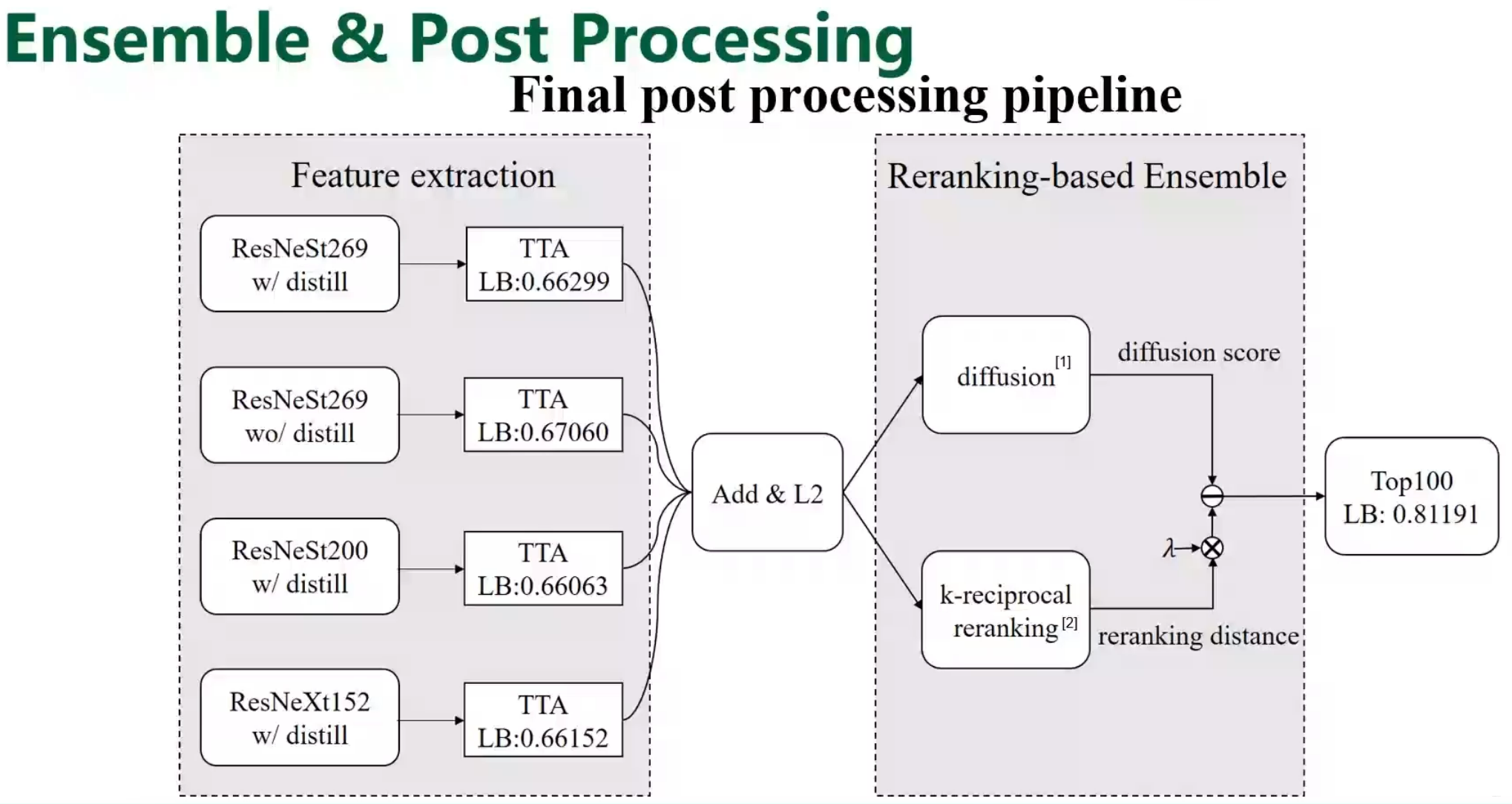
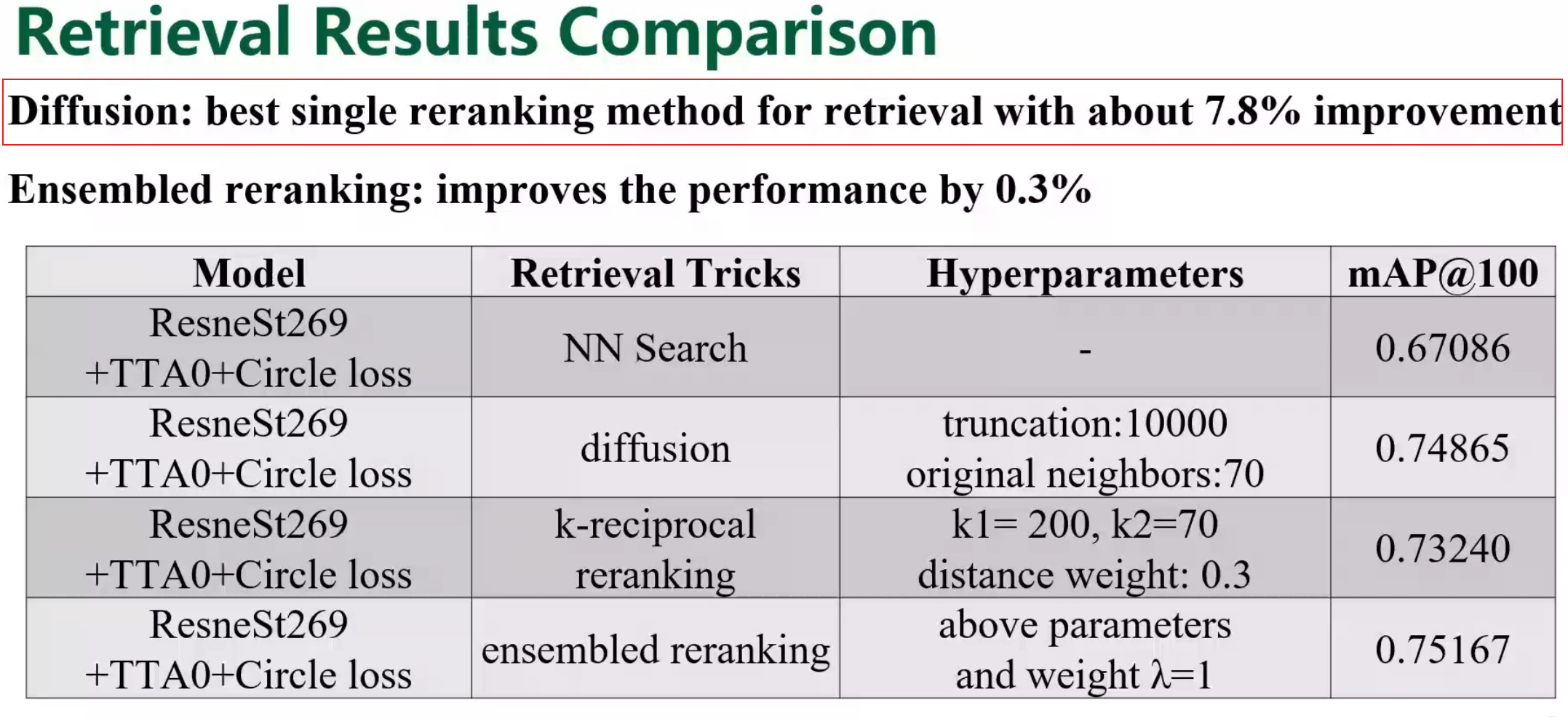
- 后处理 这部分用了两个处理,一个是diffusion和k-reciprocal reranking
检索方案对比
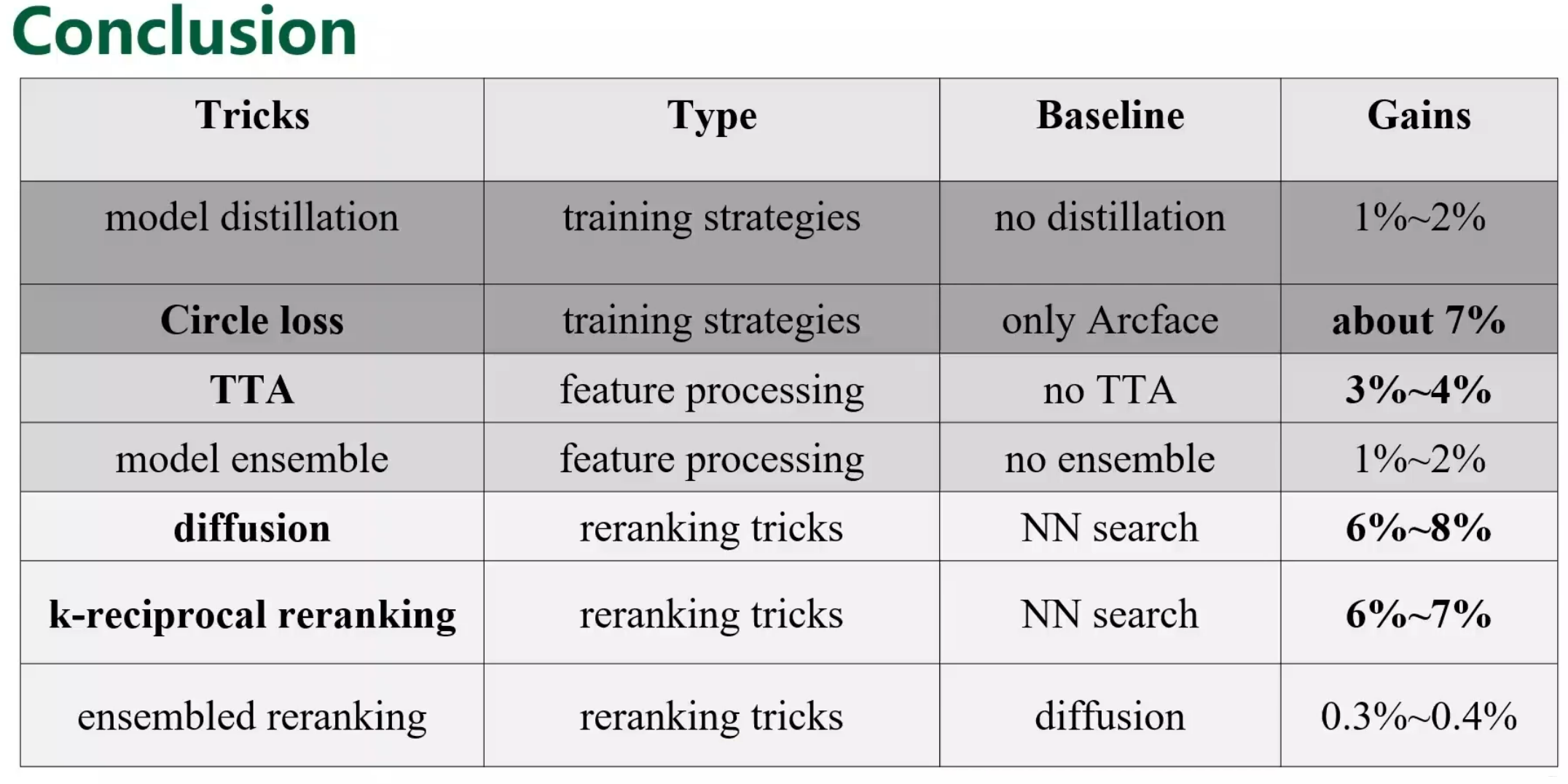
结论
华子果然不一样奥~
总结
-
数据方面:Top1,2均进行了五折数据清洗,重新生成了一个新的数据集
-
数据增强方面:CutMix,大尺寸的resize,RandAugment, weighted data sampler
-
模型训练: Top1使用了SAM的优化器,(后期),但是训练比较慢,常和交叉熵损失放在一起用,提 高模型泛化性。Top3使用的是cosine annealing的scheduler
-
模型选择:Swin,Efnt,resneSt269(没怎么见过)
-
Loss:circle loss和arcface 或者组合
-
后处理:L2Norm, DBA , distance,QE。其中TOP1 Euclidean和Jacobian distance,Top2是cos,top3使用了diffusion和k-reciprocal reranking检索方法,均使用了TTA
-
其中Top3还使用了对模型进行蒸馏的操作1-2%的提升,比较新颖。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)