(Python实现)数据PCA降维白化和L2归一化-深度学习实践常用数据预处理
在深度学习网络训练之前,一般需要对数据进行预处理1:减去均值,然后归一化2:PCA白化本文从python代码实现的角度去实现它首先生成一个随机数组用于实验,维度是(40,500),代表有40个样本,每个样本的维度是500维。from numpy import randomX= random.random(size=(40,500))1:减去均值,然后归一化X -= np.mean(
在深度学习网络训练之前,一般需要对数据进行预处理
1:减去均值,然后归一化
2:PCA白化
本文从python代码实现的角度去实现它
首先生成一个随机数组用于实验,维度是(40,500),代表有40个样本,每个样本的维度是500维。
from numpy import random
X= random.random(size=(40,500))1:减去均值,然后归一化
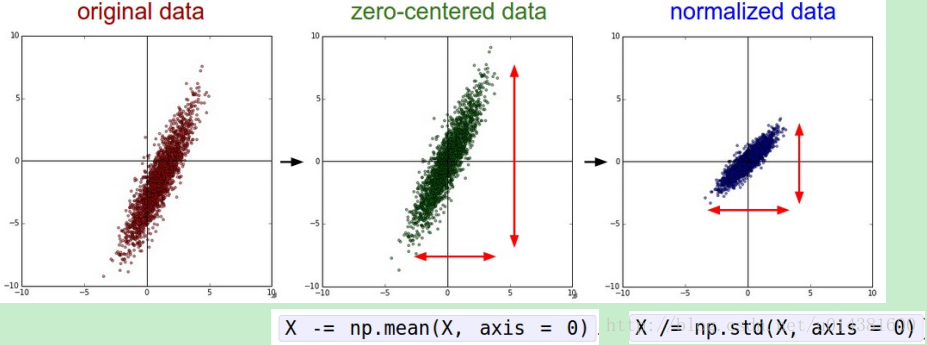
X -= np.mean(X, axis = 0) # 减去均值,使得以0为中心
X /= np.std(X, axis = 0) # 归一化这样归一化以后数据X就被归一化到-1到1的范围内。
数据可视化的效果就是:
2: PCA Whitening,PCA白化也是一种常用的数据预处理:
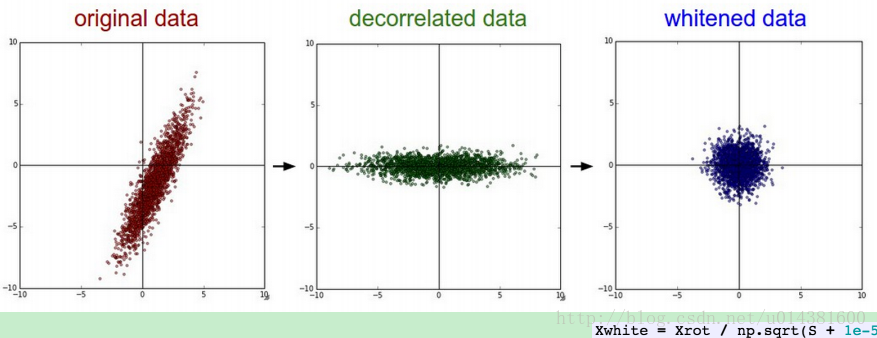
X -= np.mean(X, axis = 0) # 减去均值,使得以0为中心
cov = np.dot(X.T, X) / X.shape[0] #计算协方差矩阵
U,S,V = np.linalg.svd(cov) #矩阵的奇异值分解
Xrot = np.dot(X, U)
Xwhite = Xrot / np.sqrt(S + 1e-5) #加上1e-5是为了防止出现分母为0的异常最后的Xwhite 参数就是白化后的数据,维度依然是(40,500)
数据可视化的效果就是:
一般深度神经网络CNN中不用用PCA白化,但是1:减去均值,然后归一化一般是必须的,如果是caffe的话在prototxt就是减去图片的meanfile!
新增:python对数据进行L2 norm
需要用到sklearn 库,安装见http://scikit-learn.org/stable
from sklearn import preprocessing
help(preprocessing.normalize)显示如下:
normalize(X, norm='l2', axis=1, copy=True)
Scale input vectors individually to unit norm (vector length).
Read more in the :ref:`User Guide <preprocessing_normalization>`.
Parameters
----------
X : {array-like, sparse matrix}, shape [n_samples, n_features]
The data to normalize, element by element.
scipy.sparse matrices should be in CSR format to avoid an
un-necessary copy.
norm : 'l1', 'l2', or 'max', optional ('l2' by default)
The norm to use to normalize each non zero sample (or each non-zero
feature if axis is 0).
axis : 0 or 1, optional (1 by default)
axis used to normalize the data along. If 1, independently normalize
each sample, otherwise (if 0) normalize each feature.
copy : boolean, optional, default True
set to False to perform inplace row normalization and avoid a
copy (if the input is already a numpy array or a scipy.sparse
最重要的信息就是X : {array-like, sparse matrix}, shape [n_samples, n_features],说明L2归一化的数据形式是一行为一个样本,行数代表了数据的数量,列数代表特征的维度,
因此实现L2 norm的完整python代码就是
from sklearn import preprocessing
X_L2_NORM= preprocessing.normalize(X, norm='l2')PCA降维和白化的sklearn 方法:
from sklearn.decomposition import PCA
#PCA白化处理
pca = PCA(whiten=True)
pca.fit(X)
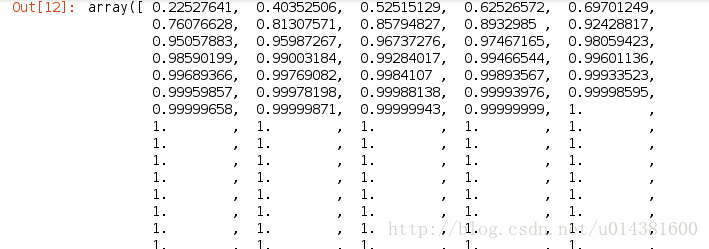
variance = pd.DataFrame(pca.explained_variance_ratio_)
np.cumsum(pca.explained_variance_ratio_)
会得到如下的结果:
选取自己需要的维度,然后
#降维后选取指定 的维度
pca = PCA(n_components=35,whiten=True)
pca = pca.fit(X)
XPCA = pca.transform(X)
print XPCA.shape
CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)