【NLP】中文分词:原理及分词算法
一、中文分词 词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。 Lucene中对中文的处理是基于自动切分的单字切分,或者二元切分。除此之外,还有最大切分(包括向前、向后、以及前后相结合)、最少切分、全切分等等。二、 中文分词
一、中文分词
词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。
Lucene中对中文的处理是基于自动切分的单字切分,或者二元切分。除此之外,还有最大切分(包括向前、向后、以及前后相结合)、最少切分、全切分等等。
二、 中文分词技术分类
我们讨论的分词算法可分为三大类:
1.基于词典:基于字典、词库匹配的分词方法;(字符串匹配、机械分词法)
2.基于统计:基于词频度统计的分词方法;
3.基于规则:基于知识理解的分词方法。
第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,如:最大匹配法、最小分词方法等。这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等问题使其难以适应开放的大规模文本的分词处理。第二类基于统计的分词方法则基于字和词的统计信息,如把相邻字间的信息、词频及相应的共现信息等应用于分词,由于这些信息是通过调查真实语料而取得的,因而基于统计的分词方法具有较好的实用性。
下面简要介绍几种常用方法:
三、基于词典分词
0. 逐词遍历法
逐词遍历法将词典中的所有词按由长到短的顺序在文章中逐字搜索,直至文章结束。也就是说,不管文章有多短,词典有多大,都要将词典遍历一遍。这种方法效率比较低,大一点的系统一般都不使用。
1. 基于字典、词库匹配的分词方法(机械分词法)
这种方法按照一定策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。识别出一个词,根据扫描方向的不同分为正向匹配和逆向匹配。根据不同长度优先匹配的情况,分为最大(最长)匹配和最小(最短)匹配。根据与词性标注过程是否相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的方法如下:
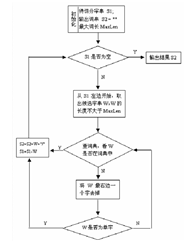
(1)最大正向匹配法(MM, MaximumMatching Method)
通常简称为MM法。其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理…… 如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止。这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。
******************************************************************************************************************************************
其算法描述如下:
step1: 从左向右取待切分汉语句的m个字符作为匹配字段,m为大机器词典中最长词条个数。
step2: 查找大机器词典并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
******************************************************************************************************************************************
(2)逆向最大匹配法(ReverseMaximum Matching Method)
通常简称为RMM法。RMM法的基本原理与MM法相同 ,不同的是分词切分的方向与MM法相反,而且使用的分词辞典也不同。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的2i个字符(i字字串)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。
由于汉语中偏正结构较多,若从后向前匹配,可以适当提高精确度。所以,逆向最大匹配法比正向最大匹配法的误差要小。统计结果表明 ,单纯使用正向最大匹配的错误率为 1/16 9,单纯使用逆向最大匹配的错误率为 1/245。例如切分字段“硕士研究生产”,正向最大匹配法的结果会是“硕士研究生 / 产”,而逆向最大匹配法利用逆向扫描,可得到正确的分词结果“硕士 / 研究 / 生产”。
当然,最大匹配算法是一种基于分词词典的机械分词法,不能根据文档上下文的语义特征来切分词语,对词典的依赖性较大,所以在实际使用时,难免会造成一些分词错误,为了提高系统分词的准确度,可以采用正向最大匹配法和逆向最大匹配法相结合的分词方案(见“双向匹配法”)
(3)最少切分法
使每一句中切出的词数最小。
(4)双向匹配法
将正向最大匹配法与逆向最大匹配法组合。先根据标点对文档进行粗切分,把文档分解成若干个句子,然后再对这些句子用正向最大匹配法和逆向最大匹配法进行扫描切分。如果两种分词方法得到的匹配结果相同,则认为分词正确,否则,按最小集处理。
四、 全切分、基于词的频度统计(无字典分词)
基于词的频度统计的分词方法是一种全切分方法。在讨论这个方法之前我们先要明白有关全切分的相关内容。
(1) 全切分
全切分要求获得输入序列的所有可接受的切分形式,而部分切分只取得一种或几种可接受的切分形式,由于部分切分忽略了可能的其他切分形式,所以建立在部分切分基础上的分词方法不管采取何种歧义纠正策略,都可能会遗漏正确的切分,造成分词错误或失败。而建立在全切分基础上的分词方法,由于全切分取得了所有可能的切分形式,因而从根本上避免了可能切分形式的遗漏,克服了部分切分方法的缺陷。
全切分算法能取得所有可能的切分形式,它的句子覆盖率和分词覆盖率均为100%,但全切分分词并没有在文本处理中广泛地采用,原因有以下几点:
1. 全切分算法只是能获得正确分词的前提,因为全切分不具有歧义检测功能,最终分词结果的正确性和完全性依赖于独立的歧义处理方法,如果评测有误,也会造成错误的结果。
2. 全切分的切分结果个数随句子长度的增长呈指数增长,一方面将导致庞大的无用数据充斥于存储数据库;另一方面当句长达到一定长度后,由于切分形式过多,造成分词效率严重下降。
(2) 基于词的频度统计的分词方法
主要思想:上下文中,相邻的字同时出现的次数越多,就越可能构成一个词。因此字与字相邻出现的概率或频率能较好的反映词的可信度。
主要统计模型为:N元文法模型(N-gram)、隐马尔科夫模型(Hidden Markov Model, HMM)。
**************************************************************************************************************************************************
HMM马尔科夫假设:一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词。
如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram。即
P(T) = P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram。
在实践中用的最多的就是bigram和trigram了,而且效果很不错。高于四元的用的很少,因为训练它需要更庞大的语料,而且数据稀疏严重,时间复杂度高,精度却提高的不多。
设w1,w2,w3,...,wn是长度为n的字符串,规定任意词wi 只与它的前两个相关,得到三元概率模型
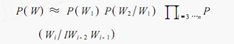
以此类推,N元模型就是假设当前词的出现概率只同它前面的N-1个词有关。
***************************************************************************************************************************************************
这是一种全切分方法。它不依靠词典,而是将文章中任意两个字同时出现的频率进行统计,次数越高的就可能是一个词。它首先切分出与词表匹配的所有可能的词,运用统计语言模型和决策算法决定最优的切分结果。它的优点在于可以发现所有的切分歧义并且容易将新词提取出来。
五、基于统计分词(无字典分词)
该方法主要基于句法、语法分析,并结合语义分析,通过对上下文内容所提供信息的分析对词进行定界,它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断。这类方法试图让机器具有人类的理解能力,需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式。因此目前基于知识的分词系统还处在试验阶段。
六、并行分词法
这种分词方法借助于一个含有分词词库的管道进行 ,比较匹配过程是分步进行的 ,每一步可以对进入管道中的词同时与词库中相应的词进行比较 ,由于同时有多个词进行比较匹配 ,因而分词速度可以大幅度提高。这种方法涉及到多级内码理论和管道的词典数据结构。(详细算法可以参考吴胜远的《并行分词方法的研究》)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)