【论文笔记】Spatial Transformer Networks
卷积神经网络(CNN)已经被证明能够训练一个能力强大的分类模型,但与传统的模式识别方法类似,它也会受到数据在空间上多样性的影响。这篇Paper提出了一种叫做空间变换网络(Spatial Transform Networks, STN),该网络不需要关键点的标定,能够根据分类或者其它任务自适应地将数据进行空间变换和对齐(包括平移、缩放、旋转以及其它几何变换等)。
参考文献:**Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Advances in Neural Information Processing Systems. 2015: 2017-2025.
摘要
卷积神经网络(CNN)已经被证明能够训练一个能力强大的分类模型,但与传统的模式识别方法类似,它也会受到数据在空间上多样性的影响。这篇Paper提出了一种叫做空间变换网络(Spatial Transform Networks, STN),该网络不需要关键点的标定,能够根据分类或者其它任务自适应地将数据进行空间变换和对齐(包括平移、缩放、旋转以及其它几何变换等)。在输入数据在空间差异较大的情况下,这个网络可以加在现有的卷积网络中,提高分类的准确性。
——————
由于我之前的工作部分涉及到人脸对齐,所以看到这篇Paper异常激动。总觉得能用它做点什么。
算法介绍
1. 算法总流程
STN 主要可以分为三个部分:1)localisation network. 2) grid generator. 3) sampler. (中文我翻译不准确,大家意会下)。localisation network用来计算空间变换的参数
θ
,grid generator则是得到input map
U∈RH×W×C
到 output map 各位置的
V∈RH′×W′×C
对应关系
Tθ
, sampler根据input map
U
和 对应关系
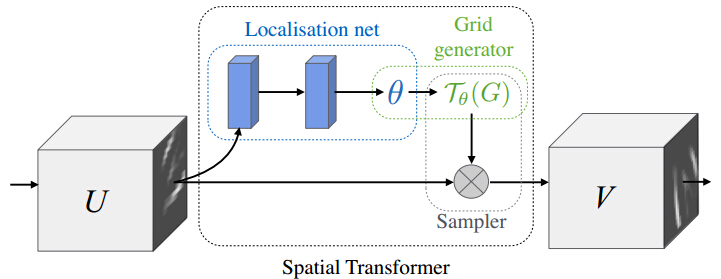
1.1 Localisation Network
它的作用就是通过一个子网络(全连接或者卷积网,再加一个回归层),生成空间变换的参数 θ 。 θ 的形式可以多样,如需实现2D仿射变换, θ 就是一个6维(2x3)向量的输出。
1.2 Parameterised Sampling Grid
假设
U
(不局限于输入图片,也可以是其它层输出的feature map)每个像素的坐标为
当然, Aθ 也可以有其它形式,如3D仿射变换,透射变换等。
1.3 Differentiable Image Sampling
在计算得到
Tθ
后,就可以由以下公式
U
得到
在求得
V
后,当然少不了上述公式对
∂Vci∂ysi 与 ∂Vci∂xsi 类似。对 θ 的求导为:
而 ∂xsi∂θ , ∂ysi∂θ 根据具体的变换函数便可得到。
通过以上3个部分的结合,便形成了完整的 STN。
2. 算法分析
STN 计算较快,几乎没有增加原有网络模型的训练时间。由于它能够在训练过程中,学习到与任务相关的空间变换参数,因此能够进一步最小化网络的损失函数。STN 不只可以用在输入的图像层,也可以加入卷积层或者其它层之后。
3. 实验结果
这篇文章分别在手写文字识别、街景数字识别、鸟类分类以及共定位等方面做了实验, 这里我只列出比较有代表性的手写文字实验部分。
实验数据为MNIST,分别在经过不同处理(包括 旋转(R)、旋转、缩放、平移(RTS),透射变换(P)),弹性变形(E))的数据上进行字符识别的实验。Baseline分别使用了两种网络结构FCN , CNN, 加入了 STN 的网络为 ST-FCN, ST-CNN。其中,STN 采用了以下几种变换方法:仿射变换(Aff )、透射变换(Proj )、以及薄板样条变换(TPS )。下表列出了 STN 与 baseline 在MNIST上的比较结果,表中数据为识别错误率:
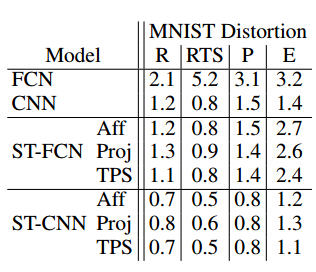
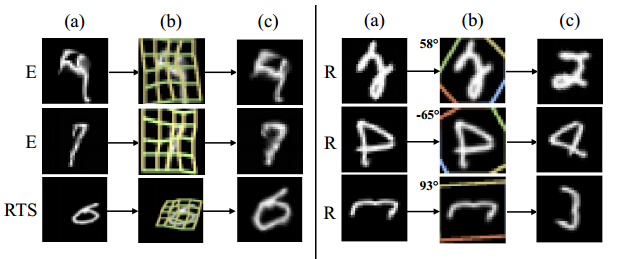
可以看出,对不同的形式的数据,加入了STN 的网络均优于 baseline 的结果。以下为 STN 对数字图像进行变换后的结果,其中a列为原始数据,b列为变换参数的示意图,c列为最终变换后的结果:
总结
STN 能够在没有标注关键点的情况下,根据任务自己学习图片或特征的空间变换参数,将输入图片或者学习的特征在空间上进行对齐,从而减少物体由于空间中的旋转、平移、尺度、扭曲等几何变换对分类、定位等任务的影响。加入到已有的CNN或者FCN网络,能够提升网络的学习能力。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)