【语音识别入门】Python音频处理示例(含完整代码)
readframes:读取声音数据,传递一个参数指定需要读取的长度(以取样点为单位),readframes返回的是。把数据变成(0,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。,通过frombuffer函数将二进制转换为整型数组,通过其参数dtype指定转换后的数据格式。首先,需要import几个工具包,一个是python标准库中的。这一步去掉也可
·
一、读取本地音频数据
首先,需要import几个工具包,一个是python标准库中的wave模块,用于音频处理操作,nump和matplot提供数据处理函数。
import wave
# 用于绘制波形图
import matplotlib.pyplot as plt
# 用于计算波形数据
import numpy as np
# 用于系统处理 读取本地音频文件
import os
# 读取本地音频数据
# 打开wave文件
f = wave.open(r"audio06.wav",'rb')
# 读取格式信息
params = f.getparams()
nchannels ,sampwidth ,framerate ,nframes = params [:4]
print(framerate)
二、读取单通道音频,并绘制波形图(常见音频为左右两个声道)
(1) 通过第一步,可以继续读取音频数据本身,保存为字符串格式
readframes:读取声音数据,传递一个参数指定需要读取的长度(以取样点为单位),readframes返回的是二进制数据(一大堆bytes),在Python中用字符串表示二进制数据。
strData = f.readframes(nframes)
(2) 如果需要绘制波形图,则需要将字符串格式的音频数据转化为 int 类型
frombuffer:根据声道数和量化单位,将读取的二进制数据转换为一个可以计算的数组,通过frombuffer函数将二进制转换为整型数组,通过其参数dtype指定转换后的数据格式。
waveData=np.frombuffer(strData,dtype=np.int16)
此处需要使用到 numpy 进行数据格式的转化
(3) 将幅值归一化
把数据变成(0,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
waveData=waveData*1.0/(max(abs(waveData)))
这一步去掉也可画出波形图,可以尝试不用此步,找出波形图的不同
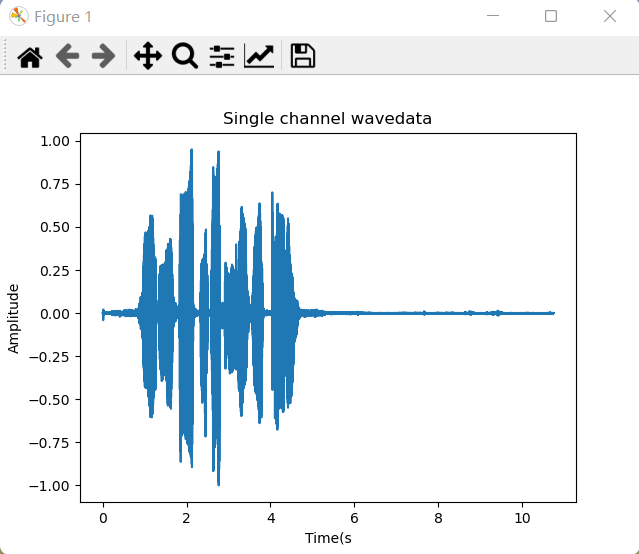
(4) 绘制图像
通过取样点数和取样频率计算出取样的时间:
time = np.arange(0,nframes)*(1.0/framerate)
(5)完整代码
import wave
# 用于绘制波形图
import matplotlib.pyplot as plt
# 用于计算波形数据
import numpy as np
# 用于系统处理 读取本地音频文件
import os
# 读取本地音频数据
# 打开wave文件
f = wave.open(r"audio06.wav",'rb')
# 读取格式信息
params = f.getparams()
nchannels ,sampwidth ,framerate ,nframes = params [:4]
print(framerate)
# 读取单通道音频 并绘制波形图(常见音频为左右两个声道)
# 读取波形数据
strData = f.readframes(nframes)
# 将字符串转换为16位整数
waveDate = np.frombuffer(strData,dtype=np.int16)
#归一化:把数据变成(0,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速
waveDate = waveDate*1.0/(max(abs(waveDate)))
# 计算音频时间
time = np.arange(0,nframes)*(1.0/framerate)
plt.plot(time,waveDate)
plt.xlabel("Time(s")
plt.ylabel("Amplitude")
plt.title("Single channel wavedata")
plt.show()


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 13
13 1
1- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)