基于循环神经网络实现基于字符的语言模型(char-level RNN Language Model)-tensorflow实现
前面几章介绍了卷积神经网络在自然语言处理中的应用,这是因为卷积神经网络便于理解并且易上手编程,大多教程(比如tensorflow的官方文档就先CNN再RNN)。但RNN的原理决定了它先天就适合做自然语言处理方向的问题(如语言模型,语音识别,文本翻译等等)。因此接下来一段时间应该会着重研究RNN,LSTM,Attention等在NLP的应用及其tensorflow实现。在介绍本篇文章之前,先推荐几篇
前面几章介绍了卷积神经网络在自然语言处理中的应用,这是因为卷积神经网络便于理解并且易上手编程,大多教程(比如tensorflow的官方文档就先CNN再RNN)。但RNN的原理决定了它先天就适合做自然语言处理方向的问题(如语言模型,语音识别,文本翻译等等)。因此接下来一段时间应该会着重研究RNN,LSTM,Attention等在NLP的应用及其tensorflow实现。
在介绍本篇文章之前,先推荐几篇学习内容:
语言模型部分:
1、CS224d 第四篇notes,首先讲语言模型的问题,然后推导了RNN、biRNN和LSTM。比99%的中文博客要靠谱。
2、language model and word2vec,前半部分是语言模型,后半部分介绍了Skip-gram等模型,并引入word2vec。
RNN和LSTM部分:
1、The Unreasonable Effectiveness of Recurrent Neural Networks 该文主要介绍了RNN在NLP中的应用,很直观。
2、Understanding LSTM Networks LSTM过程中很完美的公式,相信看一遍就能记住。
3、2的中文版 对自己英文不自信的同学可以看这个译文。
本篇文章实现基于字符的RNN语言模型,源自于Understanding LSTM Networks,在该篇文章中也附有github的网址,不过是基于Torch实现的,在github上有人对其使用tensorflow重写,实现了基于字符的语言模型,我们今天就来介绍这个代码。
数据处理
数据处理两个最重要的工作
1. 将文本格式的文件转化为np格式的数组。首先构建字符或者单词的字典embedding_dic,字典的key为字符或者单词,value为该字符或单词对应的索引。其次要构造字符或者单词表embedding_w,每一行是一个字符或者单词的词向量(比如one-hot编码或者word2vec),对应的行标即为该单词的索引。
2. 生成next_batch,这里要对训练的过程进行feed的格式进行考虑,确保与占位符声明的tensorshape一致。在将所有的训练集遍历过一次以后,需要将训练集进行重排permutation。
源代码中将seq_length和batches都设置为50,这样不方便观察tensor的变化,因此在下面的代码中,我会将seq_length设置为100(只需要在train文件中更改配置参数即可)。因此一些主要参数为:
tensor_size = 1115000 #实际为1115394,1115000为取整之后的结果
batch_size = 50
seq_length = 100
num_batches = 223在源码中,po主将所有的字符存为vocab.pkl,将input.txt中的所有字符存为data.npy。这样如果之前已经有这两个文件,那么直接读取preprocessed的文件就行了,就可以不用再处理文本了。该源码中采用的数据集为莎士比亚作品集,是一个很小的数据集,但当数据集很大时,就可以节省很多时间了。这是可以借鉴的一个点。
po主通过collections.Counter、zip、map等几个函数,就将文本处理的第一步工作做完,这是该段代码可以借鉴的第二个点。第二步要创建next_batch,和我们之前使用start和end两个指针不同,该段代码直接对batches进行了分割,然后使用一个pointer指针指向下一个块儿就行了。详细信息代码中已经添加了中文注释。
# coding=utf-8
import codecs
import os
import collections
from six.moves import cPickle
import numpy as np
class TextLoader():
def __init__(self, data_dir, batch_size, seq_length, encoding='utf-8'):
self.data_dir = data_dir
self.batch_size = batch_size
self.seq_length = seq_length
self.encoding = encoding
input_file = os.path.join(data_dir, "input.txt")
vocab_file = os.path.join(data_dir, "vocab.pkl")
tensor_file = os.path.join(data_dir, "data.npy")
if not (os.path.exists(vocab_file) and os.path.exists(tensor_file)):
print("reading text file")
self.preprocess(input_file, vocab_file, tensor_file)
else:
print("loading preprocessed files")
self.load_preprocessed(vocab_file, tensor_file)
self.create_batches()
self.reset_batch_pointer()
# 当第一次训练时执行此函数,生成data.npy和vocab.pkl
def preprocess(self, input_file, vocab_file, tensor_file):
with codecs.open(input_file, "r", encoding=self.encoding) as f:
data = f.read()
# 统计出每个字符出现多少次,统计结果总共有65个字符,所以vocab_size = 65
counter = collections.Counter(data)
# 按键值进行排序
count_pairs = sorted(counter.items(), key=lambda x: -x[1])
# 得到所有的字符
self.chars, _ = zip(*count_pairs)
self.vocab_size = len(self.chars)
# 得到字符的索引,这点在文本处理的时候是值得借鉴的
self.vocab = dict(zip(self.chars, range(len(self.chars))))
# 将字符写入文件
with open(vocab_file, 'wb') as f:
cPickle.dump(self.chars, f)
# 使用map得到input文件中1115394个字符对应的索引
self.tensor = np.array(list(map(self.vocab.get, data)))
np.save(tensor_file, self.tensor)
# 如果不是第一次执行训练,那么载入之前的字符和input信息
def load_preprocessed(self, vocab_file, tensor_file):
with open(vocab_file, 'rb') as f:
self.chars = cPickle.load(f)
self.vocab_size = len(self.chars)
self.vocab = dict(zip(self.chars, range(len(self.chars))))
self.tensor = np.load(tensor_file)
self.num_batches = int(self.tensor.size / (self.batch_size *
self.seq_length))
def create_batches(self):
# tensor_size = 1115000 batch_size = 50, seq_length = 100
# num_batches = 223
self.num_batches = int(self.tensor.size / (self.batch_size *
self.seq_length))
# When the data (tensor) is too small,
# let's give them a better error message
if self.num_batches == 0:
assert False, "Not enough data. Make seq_length and batch_size small."
self.tensor = self.tensor[:self.num_batches * self.batch_size * self.seq_length]
xdata = self.tensor
ydata = np.copy(self.tensor)
# ydata为xdata的左循环移位,例如x为[1,2,3,4,5],y就为[2,3,4,5,1]
# 因为y是x的下一个字符
ydata[:-1] = xdata[1:]
ydata[-1] = xdata[0]
# x_batches 的 shape 就是 223 × 50 × 100
self.x_batches = np.split(xdata.reshape(self.batch_size, -1),
self.num_batches, 1)
self.y_batches = np.split(ydata.reshape(self.batch_size, -1),
self.num_batches, 1)
def next_batch(self):
x, y = self.x_batches[self.pointer], self.y_batches[self.pointer]
self.pointer += 1
return x, y
def reset_batch_pointer(self):
self.pointer = 0模型构建
RNN不太好理解的就是模型构建部分,几个重要的函数在下面的博客都有说明。
1、使用TensorFlow实现RNN模型入门篇2–char-rnn语言建模模型
2、解读tensorflow之rnn
理解了这几个函数,我们开始看代码。占位符placeholder有两个,分别命名为self.input_data和self.targets,值得一提的是,由于我们现在要训练的模型是language model,也就是给一个字符,预测最有可能的下一个字符,因此input和output是同型的,并且output是input的左移位,这在数据处理的时候已经提到过。placeholder只存储一个batch的data,input接收的是该字符在self.vocab中对应的index(后续会将index转成word_ embedding),每次接收一个seq_length的字符,那么,input shape=[batch_size, num_steps]。
注意:此时的num_steps,即为RNN可以回溯的步长,在该例子中,num_steps=seq_length=100。
为了解释方便,我将模型的主要部分用下图表示。
1. 首先看图1,input_shape为[batch_size, seq_length],通过lookup_embedding函数以后shape为[batch_size, seq_length, rnn_size]。需要注意的是,图4中的一个圈代表RNNcell,里边有很多神经元组成。
2. 图2中的rnn_size就是图4中一个RNNcell中神经元的个数。
3. 图2到图3的split函数,以1轴进行分割(即以seq进行分割,0轴为batch),分成图3所示一片一片的形式,再通过squeeze函数,每一片的大小变为[batch_size, rnn_size]。共有seq_length=100片。
4. 然后将每一片送入图4中的一个num_step中,上文已经说明num_steps=seq_length=100。接下来就可以开始进行训练了。此源码中的num_layers=2,因此是一个二层的RNN网络,在图4中已经画出。
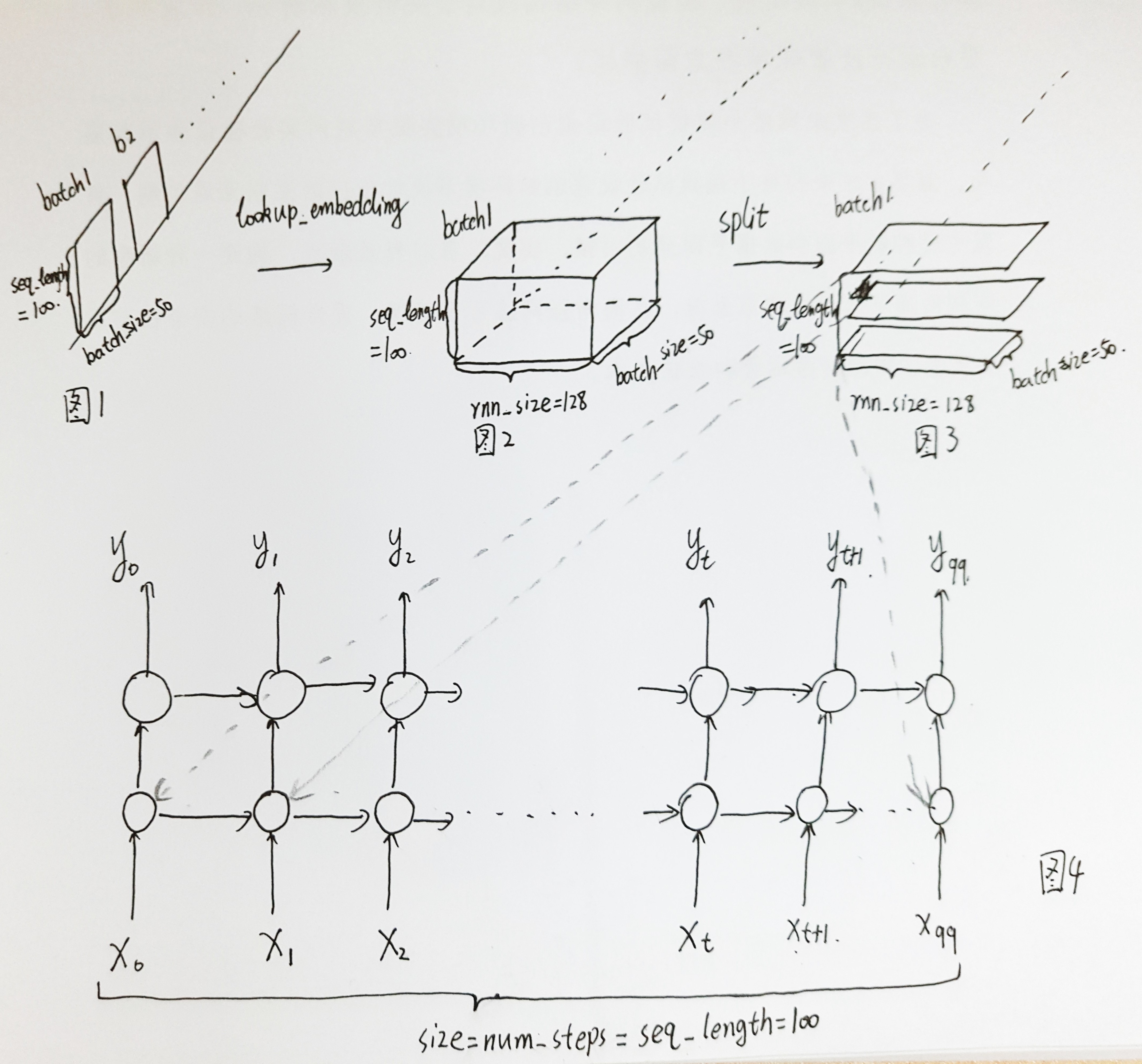
有了上述图片的解释,代码应该不难看懂:
# coding=utf-8
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.contrib import legacy_seq2seq
class Model():
def __init__(self, args, training=True):
self.args = args
if not training:
args.batch_size = 1
args.seq_length = 1
if args.model == 'rnn':
cell_fn = rnn.BasicRNNCell
elif args.model == 'gru':
cell_fn = rnn.GRUCell
elif args.model == 'lstm':
cell_fn = rnn.BasicLSTMCell
elif args.model == 'nas':
cell_fn = rnn.NASCell
else:
raise Exception("model type not supported: {}".format(args.model))
# 二层RNN,需要将rnn_size作为参数传入到rnn_cell中
cells = []
for _ in range(args.num_layers):
cell = cell_fn(args.rnn_size)
if training and (args.output_keep_prob < 1.0 or args.input_keep_prob < 1.0):
cell = rnn.DropoutWrapper(cell,
input_keep_prob=args.input_keep_prob,
output_keep_prob=args.output_keep_prob)
cells.append(cell)
# 通过cells列表,构建多层RNN,函数具体的解释可以看官网或者上文推荐的博客
self.cell = cell = rnn.MultiRNNCell(cells, state_is_tuple=True)
# 占位符的shape,图中已经解释清楚
self.input_data = tf.placeholder(
tf.int32, [args.batch_size, args.seq_length])
self.targets = tf.placeholder(
tf.int32, [args.batch_size, args.seq_length])
self.initial_state = cell.zero_state(args.batch_size, tf.float32)
# 定义需要训练的权重和偏置,因为需要和[batch,rnn_size]大小的split片相乘,
# 所以需要定义shape为[args.rnn_size, args.vocab_size]
with tf.variable_scope('rnnlm'):
softmax_w = tf.get_variable("softmax_w",
[args.rnn_size, args.vocab_size])
softmax_b = tf.get_variable("softmax_b", [args.vocab_size])
# 嵌入层,随机进行初始化
embedding = tf.get_variable("embedding", [args.vocab_size, args.rnn_size])
inputs = tf.nn.embedding_lookup(embedding, self.input_data)
# dropout beta testing: double check which one should affect next line
if training and args.output_keep_prob:
inputs = tf.nn.dropout(inputs, args.output_keep_prob)
# split函数,将图2变至图3的很多片,方便传入RNNcell
# 即[batch_size, seq_length, rnn_size]-->[batch_size, 1, rnn_size]
inputs = tf.split(inputs, args.seq_length, 1)
# squeeze函数,将大小为1的维度去掉,因此每一片的维度从[batch_size,1,rnn_size]
# 变为[batch_size,rnn_size]
inputs = [tf.squeeze(input_, [1]) for input_ in inputs]
# loop函数连接num_steps步的rnn_cell,将h(t-1)的输出prev做变换然后传入h(t)作为输入
def loop(prev, _):
prev = tf.matmul(prev, softmax_w) + softmax_b
prev_symbol = tf.stop_gradient(tf.argmax(prev, 1))
return tf.nn.embedding_lookup(embedding, prev_symbol)
"""
该函数实现了一个简单的多层rnn模型。上面的MultiRNNCell函数构造了一个时间步的多层rnn,
本函数则实现将其循环num_steps个时间步。
:param decoder_inputs:输入列表,是一个长度为num_steps的列表,
每个元素是[batch_size, input_size]的2-D维的tensor
:param initial_state:初始化状态,2-D的tensor,shape为 [batch_size x cell.state_size].
:param cell:RNNCell
:param loop_function:如果不为空,则将该函数应用于第i个输出以得到第i+1个输入,
此时decoder_inputs变量除了第一个元素之外其他元素会被忽略。其形式定义为:loop(prev, i)=next。
prev是[batch_size x output_size],i是表明第i步,next是[batch_size x input_size]。
"""
outputs, last_state = legacy_seq2seq.rnn_decoder(inputs, self.initial_state, cell, loop_function=loop if not training else None, scope='rnnlm')
out_concat = tf.concat(outputs, 1)
output = tf.reshape(out_concat, [-1, args.rnn_size])
self.logits = tf.matmul(output, softmax_w) + softmax_b
self.probs = tf.nn.softmax(self.logits)
loss = legacy_seq2seq.sequence_loss_by_example(
[self.logits],
[tf.reshape(self.targets, [-1])],
[tf.ones([args.batch_size * args.seq_length])])
self.cost = tf.reduce_sum(loss) / args.batch_size / args.seq_length
with tf.name_scope('cost'):
self.cost = tf.reduce_sum(loss) / args.batch_size / args.seq_length
self.final_state = last_state
self.lr = tf.Variable(0.0, trainable=False)
tvars = tf.trainable_variables()
# 梯度截断
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars),
args.grad_clip)
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(self.lr)
self.train_op = optimizer.apply_gradients(zip(grads, tvars))
# instrument tensorboard
tf.summary.histogram('logits', self.logits)
tf.summary.histogram('loss', loss)
tf.summary.scalar('train_loss', self.cost)
训练过程
训练部分的代码也没有新的难懂的部分,也有很多冗余的部分,所以重点关注加了注释的部分吧:
# coding=utf-8
from __future__ import print_function
import tensorflow as tf
import argparse
import time
import os
from six.moves import cPickle
from utils import TextLoader
from model import Model
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--data_dir', type=str, default='data/tinyshakespeare',
help='data directory containing input.txt')
parser.add_argument('--save_dir', type=str, default='save',
help='directory to store checkpointed models')
parser.add_argument('--log_dir', type=str, default='logs',
help='directory to store tensorboard logs')
parser.add_argument('--rnn_size', type=int, default=128,
help='size of RNN hidden state')
parser.add_argument('--num_layers', type=int, default=2,
help='number of layers in the RNN')
parser.add_argument('--model', type=str, default='lstm',
help='rnn, gru, lstm, or nas')
parser.add_argument('--batch_size', type=int, default=50,
help='minibatch size')
parser.add_argument('--seq_length', type=int, default=100,
help='RNN sequence length')
parser.add_argument('--num_epochs', type=int, default=50,
help='number of epochs')
parser.add_argument('--save_every', type=int, default=1000,
help='save frequency')
parser.add_argument('--grad_clip', type=float, default=5.,
help='clip gradients at this value')
parser.add_argument('--learning_rate', type=float, default=0.002,
help='learning rate')
parser.add_argument('--decay_rate', type=float, default=0.97,
help='decay rate for rmsprop')
parser.add_argument('--output_keep_prob', type=float, default=1.0,
help='probability of keeping weights in the hidden layer')
parser.add_argument('--input_keep_prob', type=float, default=1.0,
help='probability of keeping weights in the input layer')
parser.add_argument('--init_from', type=str, default=None,
help="""continue training from saved model at this path. Path must contain files saved by previous training process:
'config.pkl' : configuration;
'chars_vocab.pkl' : vocabulary definitions;
'checkpoint' : paths to model file(s) (created by tf).
Note: this file contains absolute paths, be careful when moving files around;
'model.ckpt-*' : file(s) with model definition (created by tf)
""")
args = parser.parse_args()
train(args)
def train(args):
# 读入数据
data_loader = TextLoader(args.data_dir, args.batch_size, args.seq_length)
args.vocab_size = data_loader.vocab_size
# check compatibility if training is continued from previously saved model
if args.init_from is not None:
# check if all necessary files exist
assert os.path.isdir(args.init_from)," %s must be a a path" % args.init_from
assert os.path.isfile(os.path.join(args.init_from,"config.pkl")),"config.pkl file does not exist in path %s"%args.init_from
assert os.path.isfile(os.path.join(args.init_from,"chars_vocab.pkl")),"chars_vocab.pkl.pkl file does not exist in path %s" % args.init_from
ckpt = tf.train.get_checkpoint_state(args.init_from)
assert ckpt, "No checkpoint found"
assert ckpt.model_checkpoint_path, "No model path found in checkpoint"
# open old config and check if models are compatible
with open(os.path.join(args.init_from, 'config.pkl'), 'rb') as f:
saved_model_args = cPickle.load(f)
need_be_same = ["model", "rnn_size", "num_layers", "seq_length"]
for checkme in need_be_same:
assert vars(saved_model_args)[checkme]==vars(args)[checkme],"Command line argument and saved model disagree on '%s' "%checkme
# open saved vocab/dict and check if vocabs/dicts are compatible
with open(os.path.join(args.init_from, 'chars_vocab.pkl'), 'rb') as f:
saved_chars, saved_vocab = cPickle.load(f)
assert saved_chars==data_loader.chars, "Data and loaded model disagree on character set!"
assert saved_vocab==data_loader.vocab, "Data and loaded model disagree on dictionary mappings!"
if not os.path.isdir(args.save_dir):
os.makedirs(args.save_dir)
with open(os.path.join(args.save_dir, 'config.pkl'), 'wb') as f:
cPickle.dump(args, f)
with open(os.path.join(args.save_dir, 'chars_vocab.pkl'), 'wb') as f:
cPickle.dump((data_loader.chars, data_loader.vocab), f)
# 构建模型
model = Model(args)
with tf.Session() as sess:
# instrument for tensorboard
summaries = tf.summary.merge_all()
writer = tf.summary.FileWriter(
os.path.join(args.log_dir, time.strftime("%Y-%m-%d-%H-%M-%S")))
writer.add_graph(sess.graph)
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver(tf.global_variables())
# restore model
if args.init_from is not None:
saver.restore(sess, ckpt.model_checkpoint_path)
# 开始训练
for e in range(args.num_epochs):
sess.run(tf.assign(model.lr,
args.learning_rate * (args.decay_rate ** e)))
data_loader.reset_batch_pointer()
state = sess.run(model.initial_state)
for b in range(data_loader.num_batches):
start = time.time()
x, y = data_loader.next_batch()
feed = {model.input_data: x, model.targets: y}
for i, (c, h) in enumerate(model.initial_state):
feed[c] = state[i].c
feed[h] = state[i].h
train_loss, state, _ = sess.run([model.cost, model.final_state, model.train_op], feed)
# instrument for tensorboard
summ, train_loss, state, _ = sess.run([summaries, model.cost, model.final_state, model.train_op], feed)
writer.add_summary(summ, e * data_loader.num_batches + b)
end = time.time()
print("{}/{} (epoch {}), train_loss = {:.3f}, time/batch = {:.3f}"
.format(e * data_loader.num_batches + b,
args.num_epochs * data_loader.num_batches,
e, train_loss, end - start))
if (e * data_loader.num_batches + b) % args.save_every == 0\
or (e == args.num_epochs-1 and
b == data_loader.num_batches-1):
# save for the last result
checkpoint_path = os.path.join(args.save_dir, 'model.ckpt')
saver.save(sess, checkpoint_path,
global_step=e * data_loader.num_batches + b)
print("model saved to {}".format(checkpoint_path))
if __name__ == '__main__':
main()
训练结果
在cpu的电脑上训练还是很快的,经过五千多步的迭代,loss能降到1.4左右。github上的代码只展示了loss,因此在这里我们也只展示loss和graph。
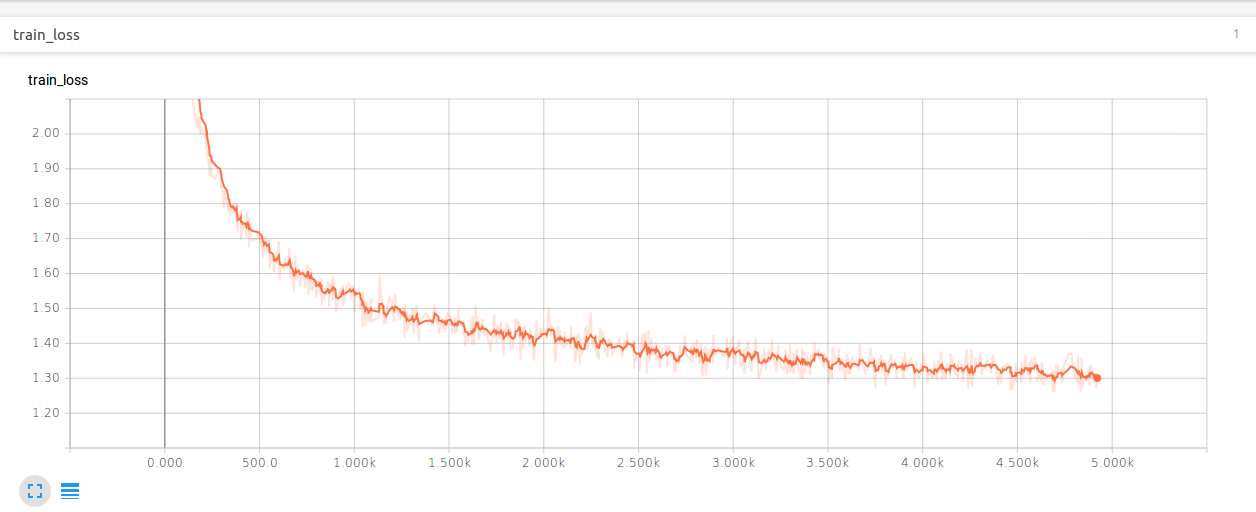
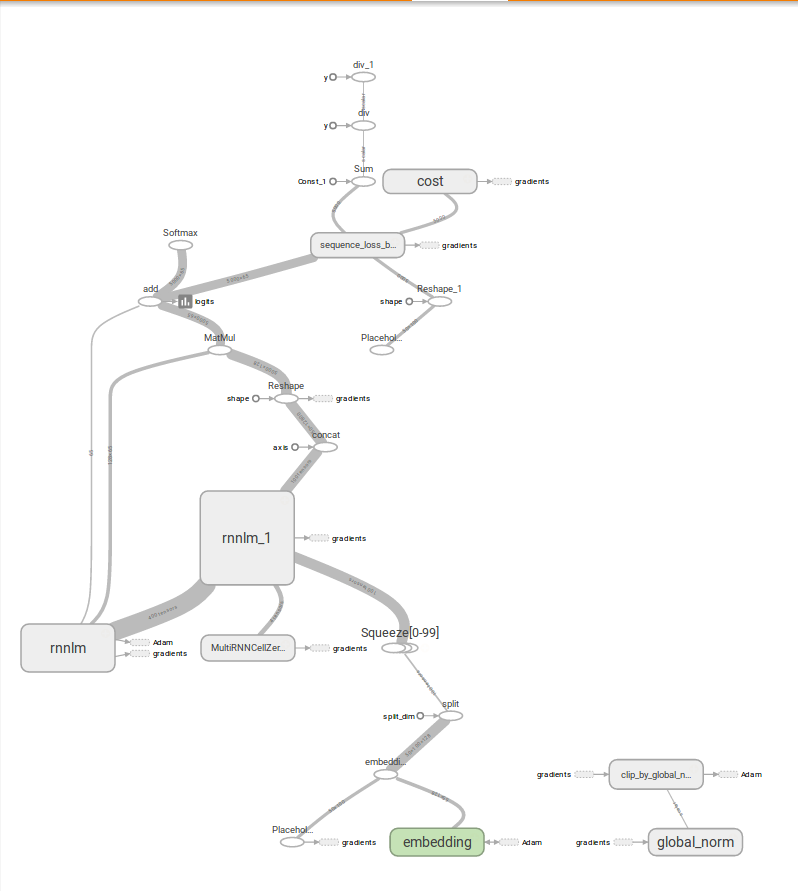

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)