LIBSvm的使用
在机器学习和模式识别领域,svm理论使用得很广泛,其理论基础是统计学习,但是如果我们的研究方向不是svm理论,我们只是利用已有的svm工具来对我们的任务进行分类和回归,那么libsvm是一个不错的选择。那么libsvm到底怎么使用呢?研究了一下,发现使用起来不是很复杂,这一小结就说说到底怎么简单的体会libsvm吧。一、 首先准备几个工具:Libsvm下载 http://www.csie.
在机器学习和模式识别领域,svm理论使用得很广泛,其理论基础是统计学习,但是如果我们的研究方向不是svm理论,我们只是利用已有的svm工具来对我们的任务进行分类和回归,那么libsvm是一个不错的选择。
那么libsvm到底怎么使用呢?研究了一下,发现使用起来不是很复杂,这一小结就说说到底怎么简单的体会libsvm吧。
一、 首先准备几个工具:
Libsvm下载 http://www.csie.ntu.edu.tw/~cjlin/libsvm/
Gnuplot下载:http://www.gnuplot.info/
Python下载: http://www.python.org/getit/
这里我下的libsvm版本为3.1.2,gnuplot版本为4.6.0,python版本为2.7.3。
其中libsvm的作用就不用多介绍了,gunplot是图像绘画工具,可以将数据可视化,python是一种程序编程语言,很方便,所以libsvm和她走得比较近。
我将libsvm解压(即相当于安装)在C:\Program Files\libsvm-3.12下
Gnuplot安装在C:\Program Files\gnuplot下
Python安装在C:\Program Files\Python27下。
二、准备环境 :
我在桌面建立了一个svm_test文件夹,将常用的几个二进制文件拷贝到该目录下,后面要用的。这些二进制文件包括svm-predict.exe,svm-scale.exe,svm-toy.exe,svm-train.exe,python.exe以及配置文件easy.py和grid.py。这些文件就在刚安装的几个软件目录中去找,这里就不列举了。如下所示:
当然并不是每一次分类和回归这些都要用到这些文件,可以自己选择,此处只是做个通用的介绍。
用文本文件打开grid.py,改变一下配置环境,在else语句后面,你可以根据自己的环境改一下。如下:

同理,easy.py也改变一下,我的改后为:

三 、准备训练的数据:
为了熟悉libsvm环境,这里我用libsvm自带svm-toy.exe来产生数据,打开svm-toy.exe显示如下:

注意到状态行的几个按钮,你自己摸索下就知道是什么用了,无需介绍。下面我产生数据如下所示:
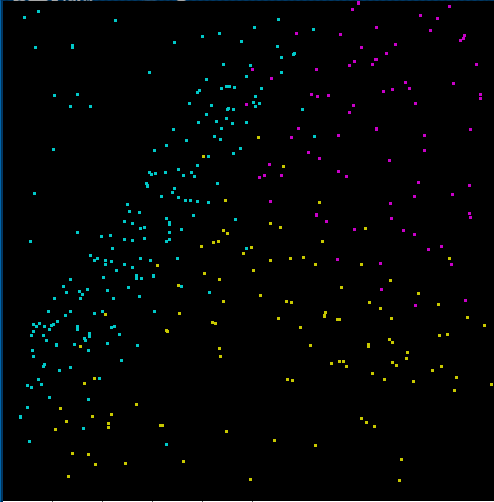
点击下面的run按钮,结果显示如下:

点击save将数据保存,我保存为before_train。
四、准备训练参数
因为svm训练需要手动调整参数,一般采用默认的情况即可,这里还是为了体验libsvm,可以用libsvm自带的grid.py来自动暴力搜索最好的参数c和g,c表示惩罚系数,g表示 gamma系数。所以我们在命令行终端输入:

这是会出现如下的界面:
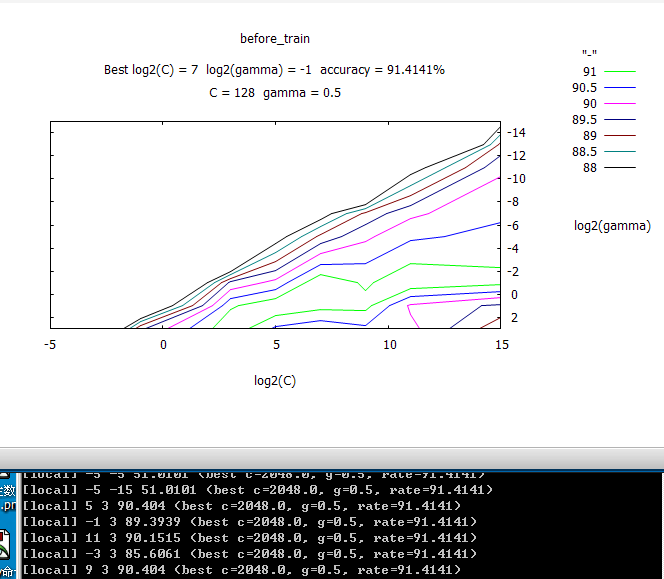
等运行完毕后在命令行终端会显示128.0 0.5 91.4141
前面那2个参数就是c和g,第三个不用管,也就是说如果我们c用128,g用0.5来训练svm数据效果是最好的。
但是在此过程中如果出现assertionerror:svm-train executable not found的错误提示:
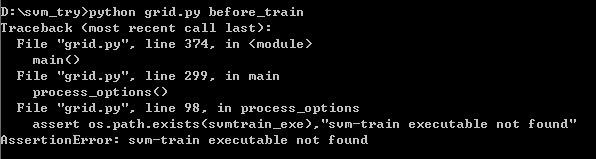
这原因是前面的grid.py没有更改与自己安装文件相对应的路径。其实我改的那些路径也未必是安装路径,因为我已经把需要用的几个exe文件复制出来了,这样很方便,换别人的电脑这些配置不用改变太多。
五、训练数据:
在命令行输入svm-train .exe –c 128 –g 0.5 before_train after_train.model

运行结果如下:
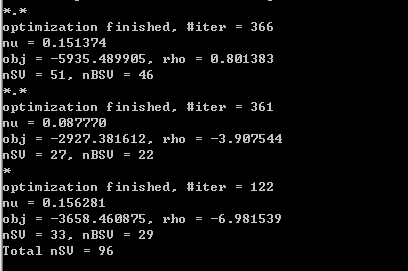
并且在相应的svm_test中输出了一个文件after_train.model。
六、预测数据。
其实我们开始就预测了下数据,只是我们用的是默认的模型,参数是-t 2 -c 100,为了对比两者的效果,我们先采用默认参数来训练:
在命令行输入:svm-train.exe before_train default_predict.model

然后用默认参数训练出的模型进行预测:
在命令行输入:svm-predict.exe before_train default_predict.model after_train_default

其结果显示如下:
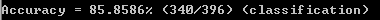
由此可见其准确率只有85.8586%.
下面我们采用用grid.py训练出的最佳参数来预测下模型,其过程和结果如下所示:

由此可见准确率提高到了91.6667%(但要注意这不一定很好,why?因为这是训练数据,有可能过拟合。)
用精确模型预测后的数据可视化显示如下:
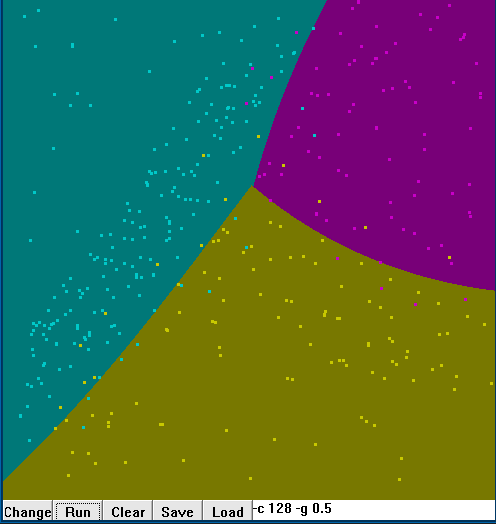
肉眼感觉不出太大的区别,不过数据摆在那里,说明grid.py还是很牛叉的!
好吧,libsvm使用的简单体验过程就先到这里。
作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 欢迎转载或分享,但请务必声明文章出处。 (新浪微博:tornadomeet,欢迎交流!)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)