python实时语音识别_Python实时语音识别控制
# Python实时语音识别控制## 概述本文中的语音识别功能采用 [百度语音识别库](http://ai.baidu.com/tech/speech/asr) ,首先利用 ***PyAudio*** 库录制语音指令,保存为受支持的 ***wav*** 音频文件,然后利用 ***百度语音识别库*** 提供的方法实现语音识别,最后检测识别结果,利用 ***PyUserInput*** 库提供的方法模
# Python实时语音识别控制
## 概述
本文中的语音识别功能采用 [百度语音识别库](http://ai.baidu.com/tech/speech/asr) ,首先利用 ***PyAudio*** 库录制语音指令,保存为受支持的 ***wav*** 音频文件,然后利用 ***百度语音识别库*** 提供的方法实现语音识别,最后检测识别结果,利用 ***PyUserInput*** 库提供的方法模拟控制web页面滚动。
百度语音识别为开发者提供业界优质且免费的语音服务,通过场景识别优化,为车载导航,智能家居和社交聊天等行业提供语音解决方案,准确率达到90%以上,让您的应用绘“声”绘色。
## 准备工作
### 安装百度语音识别SDK
```bash
pip install baidu-aip
```
### 安装Python音频处理库 ***PyAudio***
```bash
python -m pip install pyaudio
```
### 安装鼠标控制库 ***PyUserInput***
```bash
pip install pyuserinput
```
***PyUserInput*** 库依赖另外两个库 ***pywin32*** 和 ***pyHook*** ,需要单独安装。
安装方法可以参考下面这篇文章:[Win10 Python3.5安装PyUserInput](https://blog.csdn.net/ligang_csdn/article/details/54667295)
令附文中提到的资源下载链接:[lfd-pythonlibs](https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml)
另外文中提到的两个包, 需要根据自己的系统和python版本来选择。
> 如果系统是64位的,就要选择带 ***amd64*** 的。
> 如果python版本为python3.7的,就要选择带 ***cp37*** 的。
比如:***pywin32-223-cp37-cp37m-win_amd64.whl***
***pyHook-1.5.1-cp37-cp37m-win_amd64.whl***
### 申请百度开发者帐号
参考下面链接中的文章注册百度帐号,完成开发者认证,创建应用,获取密钥
[百度AI开放平台接入流程](https://ai.baidu.com/docs#/Begin/top)
## 用Pyaudio库录制音频
*Pyaudio* 是一个非常强大的音频处理库,简单几行代码即可实现音频播放,录制等功能.
百度语音识别API支持的语音格式有: *pcm(不压缩)*、*wav(不压缩,pcm编码)*、*amr(压缩格式)*.
推荐 ***pcm*** , 采样率: ***16000*** 固定值, 编码: ***16bit*** , 位深: ***单声道*** .百度服务端会将非pcm格式, 转为pcm格式, 因此使用wav, amr会有额外的转换耗时.
为了实现实时语音识别功能, 这里通过pyaudio录制一段wav格式的音频, 报文成wav音频文件, 供后续识别时调用.
```py
# 用Pyaudio库录制音频
# out_file:输出音频文件名
# rec_time:音频录制时间(秒)
def audio_record(out_file, rec_time):
CHUNK = 1024
FORMAT = pyaudio.paInt16 #16bit编码格式
CHANNELS = 1 #单声道
RATE = 16000 #16000采样频率
p = pyaudio.PyAudio()
# 创建音频流
stream = p.open(format=FORMAT, # 音频流wav格式
channels=CHANNELS, # 单声道
rate=RATE, # 采样率16000
input=True,
frames_per_buffer=CHUNK)
print("Start Recording...")
frames = [] # 录制的音频流
# 录制音频数据
for i in range(0, int(RATE / CHUNK * rec_time)):
data = stream.read(CHUNK)
frames.append(data)
# 录制完成
stream.stop_stream()
stream.close()
p.terminate()
print("Recording Done...")
# 保存音频文件
wf = wave.open(out_file, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
```
## 调用百度语音API
```py
# 读取paudio录制好的音频文件, 调用百度语音API, 设置api参数, 完成语音识别
# client:AipSpeech对象
# afile:音频文件
# afmt:音频文件格式(wav)
def aip_get_asrresult(client, afile, afmt):
# 选项参数:
# cuid String 用户唯一标识,用来区分用户,填写机器 MAC 地址或 IMEI 码,长度为60以内
# dev_pid String 语言类型(见下表), 默认1537(普通话 输入法模型)
# 识别结果已经被SDK由JSON字符串转为dict
result = client.asr(get_file_content(afile), afmt, 16000, {"cuid": CUID, "dev_pid": DEV_PID,})
#print(result)
# 如果err_msg字段为"success."表示识别成功, 直接从result字段中提取识别结果, 否则表示识别失败
if result["err_msg"] == "success.":
#print(result["result"])
return result["result"]
else:
#print(result["err_msg"])
return ""
```
### dev_pid 参数列表
| dev_pid | 语言 | 模型 | 是否有标点 | 备注 |
| :---: | :---: | :---: | :---: | :---: |
| 1536 | 普通话(支持简单的英文识别) | 搜索模型 | 无标点 | 支持自定义词库 |
| 1537 | 普通话(纯中文识别) | 输入法模型 | 有标点 | 不支持自定义词库 |
| 1737 | 英语 | | 有标点 | 不支持自定义词库 |
| 1637 | 粤语 | | 有标点 | 不支持自定义词库 |
| 1837 | 四川话 | | 有标点 | 不支持自定义词库 |
| 1936 | 普通话远场 | 远场模型 | 有标点 | 不支持 |
## 控制(鼠标)页面滚动
```py
# 控制鼠标滚动
def mouse_control(dir_tr):
MOVE_DX = 5 # 每次滚动行数
ms = PyMouse()
horizontal = 0
vertical = 0
if dir_tr.find("上") != -1: # 向上移动
vertical = MOVE_DX
#print("vertical={0}, 向上".format(vertical))
elif dir_tr.find("下") != -1: # 向下移动
vertical = 0 - MOVE_DX
#print("vertical={0}, 向下".format(vertical))
elif dir_tr.find("左") != -1: # 向左移动
horizontal = 0 - MOVE_DX
#print("horizontal={0}, 向左".format(horizontal))
elif dir_tr.find("右") != -1: # 向右移动
horizontal = MOVE_DX
#print("horizontal={0}, 向右".format(horizontal))
#print("horizontal, vertical=[{0},{1}]".format(horizontal, vertical))
# 通过scroll(vertical, horizontal)函数控制页面滚动
# 另外PyMouse还支持模拟move光标,模拟鼠标click,模拟键盘击键等
ms.scroll(vertical, horizontal)
```
## 完成实时语音识别控制
```py
while(True):
# 请说出语音指令,例如["向上", "向下", "向左", "向右"]
print("\n\n==================================================")
print("Please tell me the command(limit within 3 seconds):")
#print("Please tell me what you want to identify(limit within 10 seconds):")
audio_record(AUDIO_OUTPUT, 3) # 录制语音指令
print("Identify On Network...")
asr_result = aip_get_asrresult(client, AUDIO_OUTPUT, AUDIO_FORMAT) # 识别语音指令
if len(asr_result) != 0: # 语音识别结果不为空,识别结果为一个list
print("Identify Result:", asr_result[0])
print("Start Control...")
mouse_control(asr_result[0]) # 根据识别结果控制页面滚动
print("Control End...")
if asr_result[0].find("退出") != -1: # 如果是"退出"指令则结束程序
break;
time.sleep(1) # 延时1秒
```
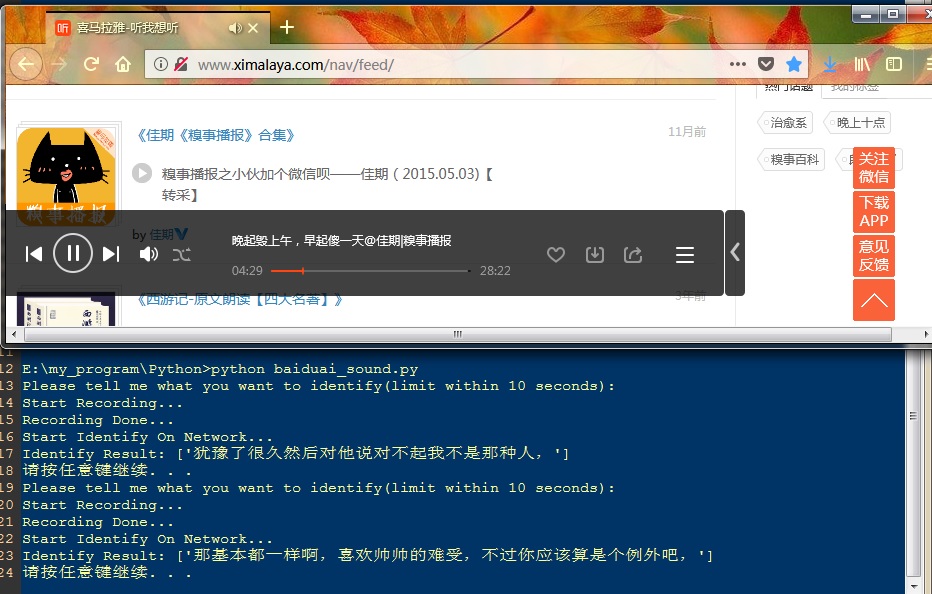
## 程序运行截图
### 语音识别
### 语音控制
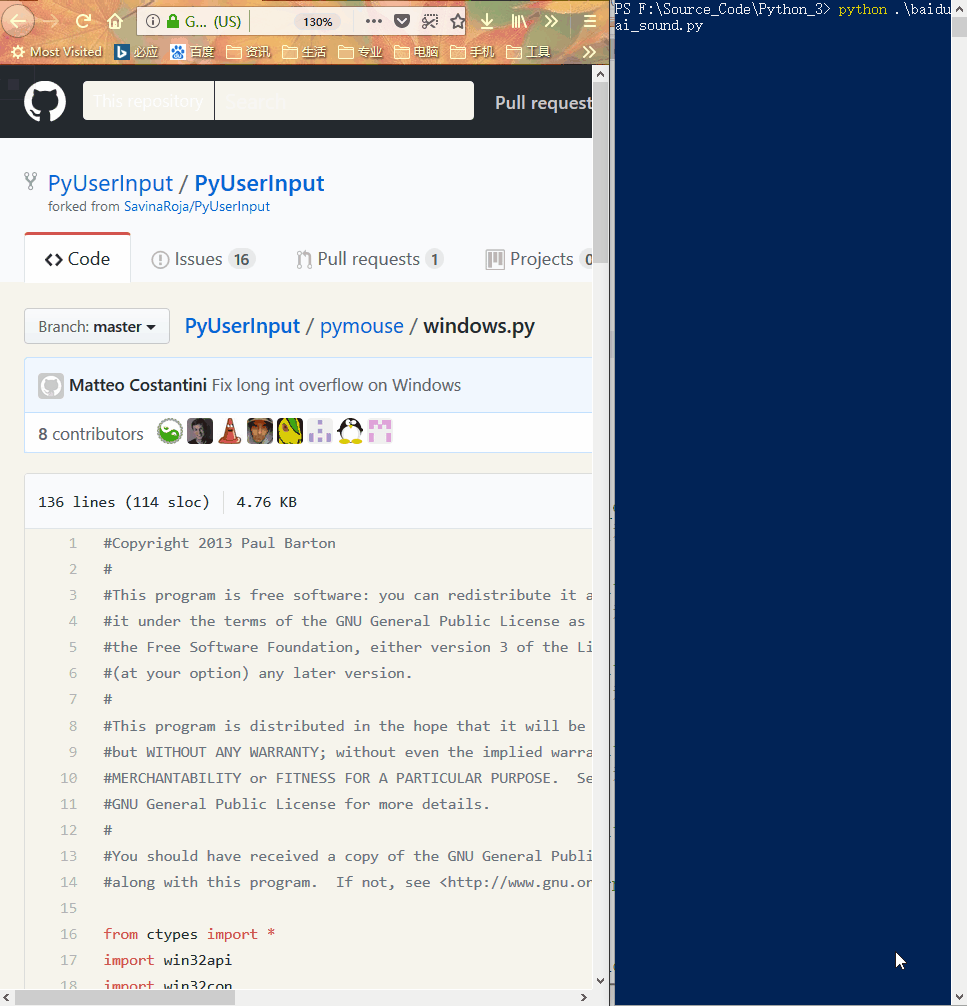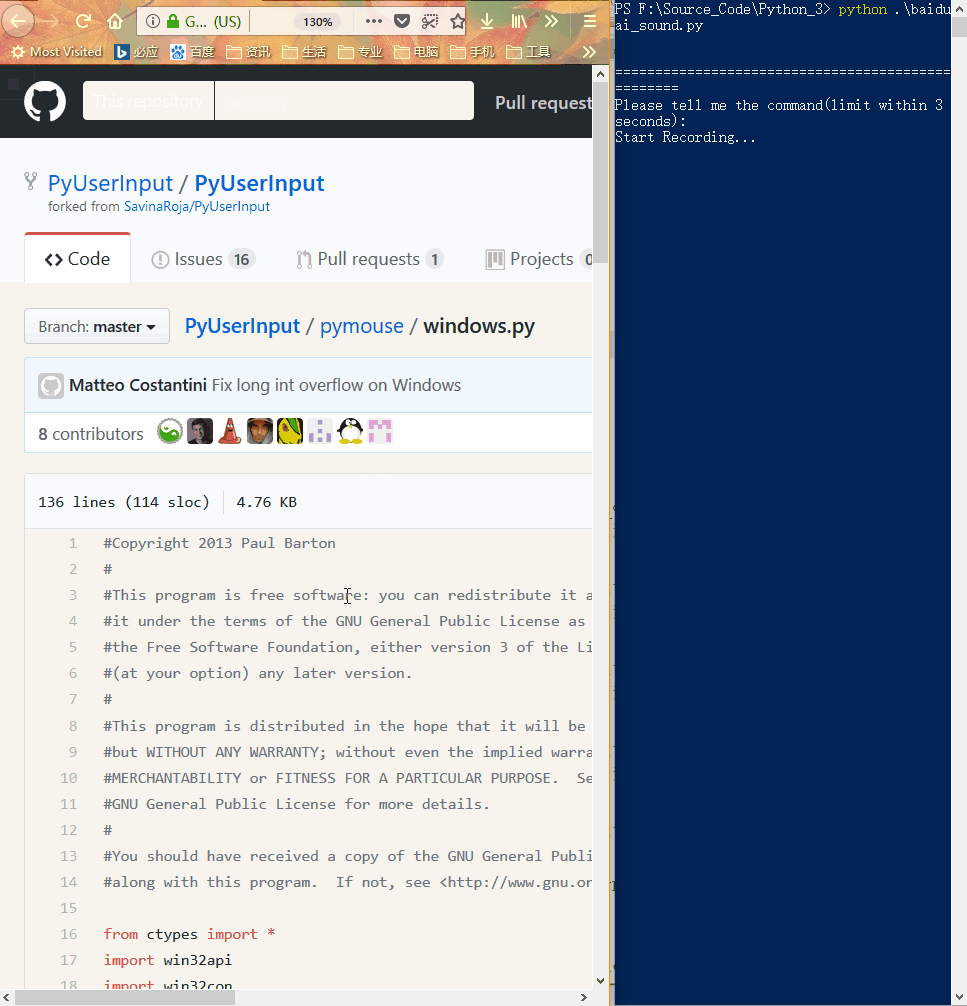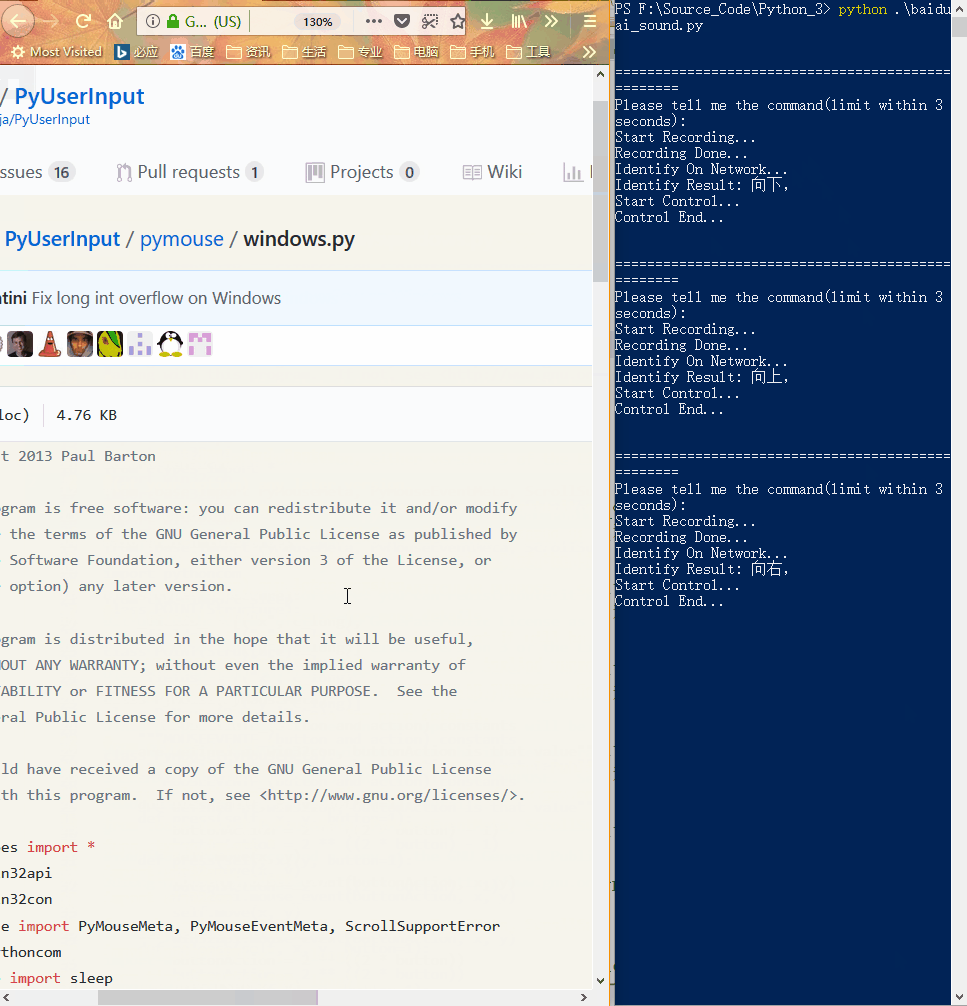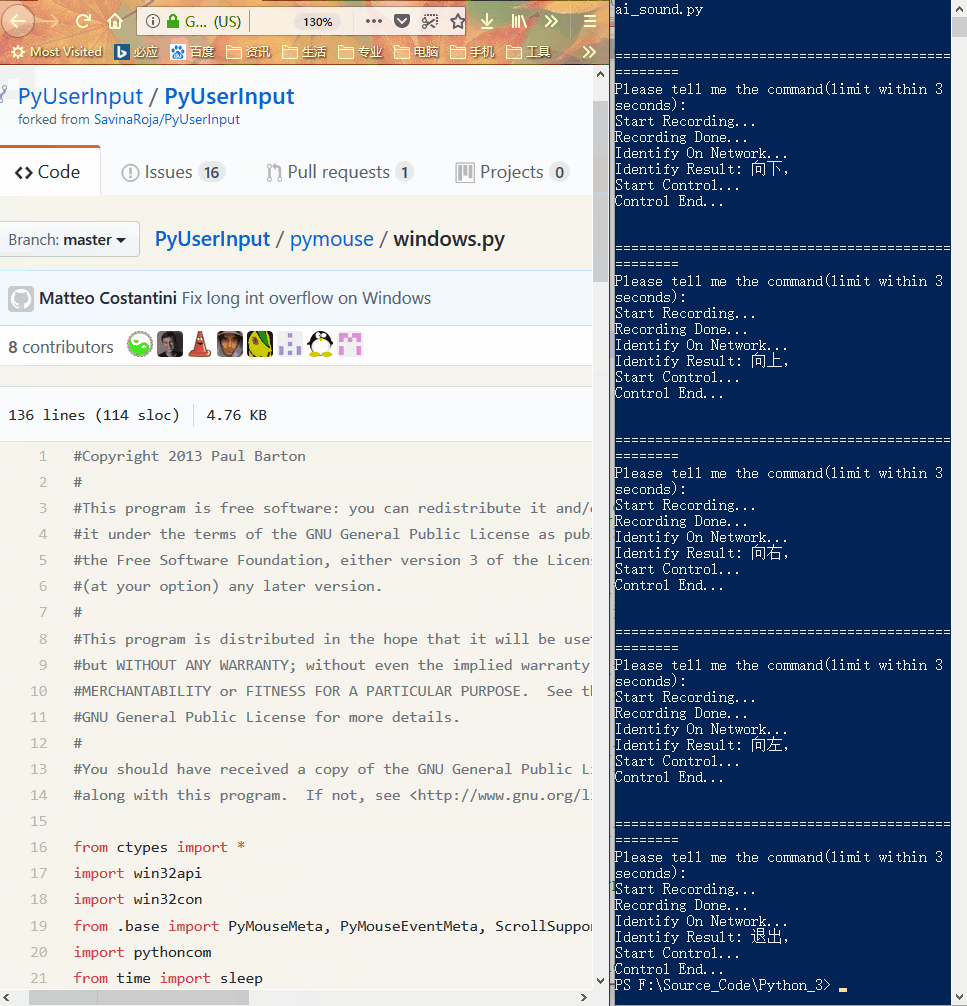
## 项目内文件截图


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)